Tanya Clement is Assistant Professor in the School of Information at the University of Texas at Austin. Her research centers on scholarly information infrastructure as it impacts academic research, research libraries, and the creation of research tools and resources in the digital humanities. She has published in a wide range of publications including Cultural Analytics, Digital Humanities Quarterly, and Information & Culture. Her research on the development of computational methods to enhance description, analysis, and access to audio collections has been supported by the National Endowment for the Humanities and the Institute of Museum and Library Services.
Thomas: You’ve spent a great deal of time researching and developing infrastructure to support computational analysis of recorded sound. A bit later I’ll be asking more about that, but I’m curious where your interest in infrastructure, the affordances of digital vs. analog media, and possibilities for Humanistic inquiry latent in various computational approaches began? Was it a product of your graduate training, or some other combination of experiences?
Tanya: The most time I spent on the family’s Apple IIe when I was little was to play a bowling game. I did play one text-based game, but it wasn’t the ones you hear spoken about by most DH scholars, not Oregon Trail or Colossal Cave Adventure. In the game I played, the title of which I cannot recall, I died from botulism after opening a can of food. I should have known – the can was dented.

Most likely my original interest in infrastructure came from math. My older brother who went on to become a kind of a math whiz, somehow figured out early on that math was a creative endeavor. You could do it all kinds of ways, even if the teachers only show you how to do it one way in school. So, when I didn’t understand things at school (which was often), I would go home and figure it out for myself — pencils and erasers and books spread out all over the glass kitchen table. I approached a math problem as a constructed thing. I learned that I just had to figure out the best ways to build the math in order to use it towards a solution.
[pullquote]Literature was (and remains) a miraculous thing to me, an incredible thing that humans build.[/pullquote] Literature was (and remains) a miraculous thing to me, an incredible thing that humans build. Many in DH, tinkerers all, talk about a desire to know how things are built. The same was true for me in math and in fiction. When I did my MFA in Fiction at UVa (1998-2000), my primary question was how did that author work that language to that effect? How does she build a person, a family, a community, a society, or a universe out of words on the page? While I was working on my MFA, I had a GAship in the Institute for Advanced Technologies in the Humanities at UVa, which was being run at the time by John Unsworth, and in the eText Center, which was headed by David Seaman. I worked at both for a semester, and these jobs led me to a job as a Project Designer at Apex CoVantage. At the time, Apex was contracted by ProQuest and Chadwick Healey to digitize their microfilm collections, one of which was Early English Books Online (EEBO), among others. The history of EEBO’s digitization is described elsewhere (see History of Early English Books Online, Transcribed by hand, owned by libraries, made for everyone: EEBO-TCP in 2012 [PDF]), alongside the collection’s oddities, so it is not shocking to point out that digitizing EEBO was not an exact science and that the collection remains today riddled with inexactitudes beyond anyone’s control. This job brought me close to the complexities behind building important digitized heritage collections, however, which remains a central interest for me.

I could see that our cultural heritage and the infrastructures, both social and technical, that sustain them, preserve them and make them accessible to us were constructed things – and, as all human-made things, constructed more or less well. In my graduate degree at the University of Maryland and in working on DH projects at the Maryland Institute for Technology in the Humanities (MITH), I learned that we have some agency and that telling the stories of a person, family, community, or society well depends on our enacting that agency in the humanities. Already concerned with considerations for the inexactitudes of representing the complexities of human culture, humanists are best situated to get our books and pencils out, spread them on the glass kitchen table, and work towards the best ways to build and sustain our cultural heritage in the digital age.
Thomas: I really appreciate the perspective of enacting agency through the Humanities. Over the past few years you’ve exercised that agency, in part, to develop computational use of audio collections in the Humanities. What are the primary opportunities and challenges in this space as they pertain to infrastructure?
Tanya: Libraries and archives hold large collections of audiovisual (AV) recordings from a diverse range of cultures and contexts that are of interest in multiple communities and disciplines. Historians, linguists, literary scholars, and biologists use AV recordings to document, preserve, and study dying languages, performances and storytelling practices, oral histories, and animal behaviors. Yet, libraries and archives lack tools to make AV collections discoverable, especially for those collections with noisy recordings – recordings created in the forest (or other “crowded” ecological landscapes), on the street, with a live audience, in multiple languages or in languages for which there are no existing dictionaries. These “messy” spoken word and non-verbal recordings lie beyond the reach of emerging automatic transcription software, and, as a result, remain hidden from Web searches that rely on metadata and indexing for discoverability.

Further, these large AV collections are not well represented in our National Digital Platform. The relative paucity of AV collections in the Europeana Collections, in the Digital Public Library of America (DPLA), the HathiTrust Digital Library (HTDL) and the HathiTrust Research Center (HTRC) for instance, is a testament to the difficulties that the Galleries, Libraries, Archives, and Museums (GLAM) community faces in creating access to their AV collections. Europeana is comprised of 59% images and 38% text objects, but only 1% sound objects and less than 1% video objects. DPLA reports that at the end of 2014 it was comprised of 51% text and 48% images with only 0.11% sound objects, and 0.27% video objects. At this time, HTDL and HTRC do not have any AV materials.
The reasons behind these lack of resources range from copyright and sensitivity concerns to the current absence of efficient technological strategies for making digital real-time media accessible to researchers. CLIR and the LoC have called for, “ . . . new technologies for audio capture and automatic metadata extraction” (Smith, et. al, 2004 [PDF]), with a, “ . . . focus on developing, testing, and enhancing science-based approaches to all areas that affect audio preservation” (Nelson-Straus, B., Gevinson, A., and Brylawski, S. 2012, 15 [PDF]). Unfortunately, beyond simple annotation and visualization tools or expensive proprietary software, open access software for accessing and analyzing audio using “science-based approaches” has not been used widely. When it is used with some success, it is typically on well-produced performances recorded in studios, not, for example, on oral histories made adhoc on the street.
[pullquote]Can we make data about sound collections verbose enough to enable an understanding of a collection even if and when that collection is out of hearing reach because of copyright or privacy restrictions?[/pullquote] We need to do a lot of work to better prepare for infrastructures that can better facilitate access to audio especially at the level of usability, efficacy, and sustainability. For instance, we don’t know what kinds of interfaces facilitate the broad use of large-scale “noisy” AV analyses from a diverse range of disciplines and communities? Sound analysis is pretty technical. How do we learn to engage with its complexities in approachable ways? Further, how much storage and processing power do users need to conduct local and large-scale AV analyses? Finally, what are local and global scale sustainability issues? What metadata standards (descriptive or technical) map to these kinds of approaches? Can we make data about sound collections verbose enough to enable an understanding of a collection even if and when that collection is out of hearing reach because of copyright or privacy restrictions?
Thomas: Now seems like a good time to discuss your audio collection infrastructure development. If you were to focus on a couple of examples of how this work specifically supports access and analysis what would they be?
Tanya: Specifically, we’ve been working on developing a tool called ARLO that was originally developed by David Tcheng, who used to be a researcher at the Illinois Informatics Institute at the University of Illinois Urbana Champaign and Tony Borries, a consultant who lives in Austin, Texas. They had created ARLO to help an ornithologist David Enstrom (also from UIUC) to use machine learning to find specific bird calls in the hundreds of hours of recordings that he had collected. Recording equipment has become much more powerful and cheaper over the last decade and scholars and enthusiasts from all kinds of disciplines have more recordings than possible human hours to analyze it all. Our hope is to develop ARLO so that people have a means of creating data about their audio so that they can analyze that data, share it, or otherwise create information about the collections that can make them discoverable.
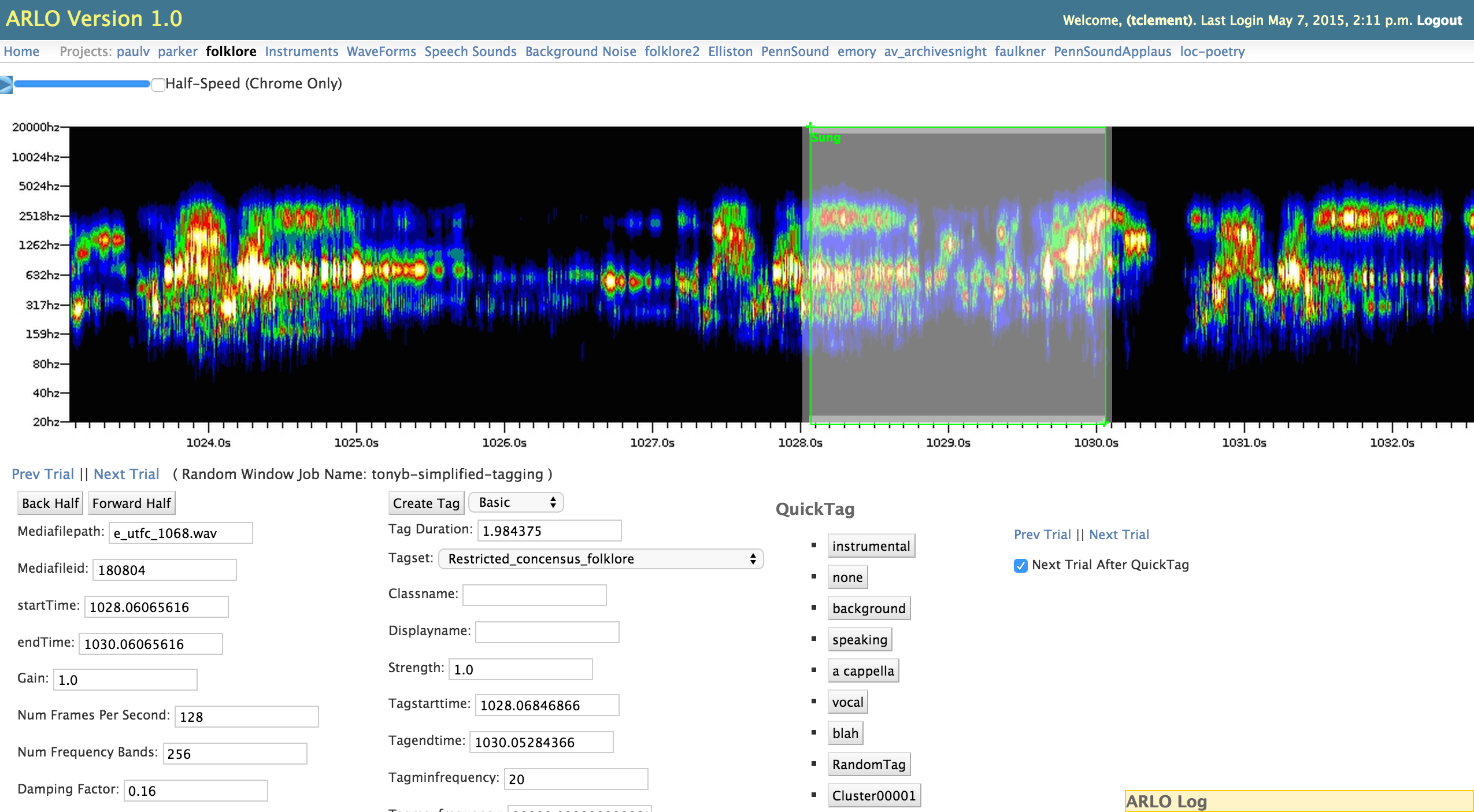
We are still very much in the research and development phase, but we have worked on a few of our own projects and helped some other groups in our attempt to learn more about what scholars and others might want in such a tool. For example, in a piece I wrote last year I talk about a project we undertook to analyze the Alan Lomax Collection at the John A. Lomax Collection in UT Folklore Center Archives at the Dolph Briscoe Center for American History at that University of Texas at Austin. We used machine learning to find instrumental, sung, and spoken sections in the collection. Using that data, we visualized these patterns across the recordings. It was really the first time such a “view” was afforded of the collection and it sparked a discussion about how the larger folklore collection at UT reflected the changing practices of ethnography and field research in folklore studies from the decades represented by the Lomax collection to those in more recent decades. With the help of Hannah Alpert-Abrams, PhD candidate in Comparative Literature at UT, we used ARLO in a graduate course being taught at LLILAS Benson Latin American Studies and Collections by Dr. Virginia Burnett called History of Modern America through Digital Archives classroom. Students identified sounds of interest in the Radio Venceremos collection of digital audio recordings of guerrilla radio from the civil war in El Salvador. Some of the sounds students used ARLO to find included bird calls, gunfire, specific word sequences, and music.
In another project School of Information PhD candidate, Steve McLaughlin and I used ARLO to analyze patterns of applause across 2,000 of PennSound’s readings. We discovered different patterns of applause in the context of different poetry reading communities. These results are more provocative than prescriptive, but our hope was to show that these kinds of analyses were not only possible but productive. We are still working through how to approach challenges in this work that come up in the form of usability (What kinds of interfaces and workflows are most useful to the community?), efficacy (For what kinds of research and pedagogical and practical goals could ARLO be most useful?), and scalability (How do we make such a tool accessible to as many people as possible?).
Thomas: In An Information Science Question in DH Feminism, you argue for a number of ways that feminist inquiry can help us better understand epistemologies that shape digital humanities and information science infrastructure development. How has this perspective concretely shaped your own work and thinking in this space?
Tanya: What has shaped my work is very much in line with this piece. Many people in STS (Science and Technology Studies) and information studies have written about the extent to which information work and information infrastructures are invisible work (Layers of Silence, Arenas of Voice: The Ecology of Visible and Invisible Work). Feminist inquiry has always been about making the invisible aspects of society more apparent, but it is also about how you take stock of those perspectives in your articulation of research. Everyone’s perspective is shaped by gender (or, really, the construct of gender) but it is also influenced by other aspects of your situated perspectives in the world including your nationality, your ability status, your day-to-day living as a parent, a child, a sibling, a spouse, a friend or any other aspect of your personhood that shapes the way you address and understand the world.
[pullquote]I’ve tried to advocate for developing tools, infrastructures, and protocols that invite others to address research questions according to their own needs.[/pullquote] The concrete ways (the particular or specific ways) that my own situated look at the world has shaped my own work is perhaps less interesting than the ways I’ve tried to advocate for developing tools, infrastructures, and protocols that invite others to address research questions according to their own needs. One aspect of ARLO that continues to intrigue me is the possibility of searching sound with sound. You choose a sound that interests you, you mark it, and you ask the machine to find more of those sounds. Now, what I like about this scenario is that a linguist might mark a sound because it includes a diphthong; someone else might mark the same sound because of the tone; a third person might be interested in the fact that this same snippet is spoken by an older man, a younger woman, or a child.
That our understanding of sound is based on a situated interpretation seems readily apparent especially compared to search scenarios in which words seem to pass as tokens that once represented complex ideas. You can mark gunshots or laughter or code switching moments when a person uses one language intermittently to express something that a society’s dominant language (let’s say English) can’t quite express. The general point or hope is that the process of choosing a sound for searching can be inviting in ways that are different from the process of choosing a single search term. In comparison to using search terms taken out of context, sound snippets remain more complex even with the absent presence of the missing context. It’s as if sounds have more dimensions, even if they clipped from a longer recording. I like working with sound for these reasons.
Thomas: Whose data praxis would you like to learn more about?
Tanya: There is quite a bit of data work going on in digital humanities that is interesting. I appreciate Lauren Klein’s attempt to unravel different histories of data visualization to help us better understand where we are by looking at from where we’ve come as well as Christine Borgman’s Big Data, Little Data, No Data: Scholarship in the Networked World, which exposes the daily practices of scholars who work with data and how those practices influence interpretation.
I have been lucky to participate in the inaugural issue of the Journal of Cultural Analytics, which is an attempt to provide a platform for showcasing how researchers in the humanities can use data to study literature, culture, media and history. Further, Digital Pedagogy in the Humanities: Concepts, Models, and Experiments, in which Daniel Carter and I have written about ten pedagogical assignments that seek to teach students about the situated elements of data in terms of its collection and use. With each of these examples, I am drawn to work that invites us to critique or understand data as a deeply political phenomenon.