The Digital Humanities Collaborative of North Carolina (DHC-NC), formerly known as The Triangle Digital Humanities Network (TDHN), is a cross-institutional community of practice for the digi-curious humanists in North Carolina. The mission of the DHC-NC is to promote DH projects and practices across North Carolina in an inclusive and equitable fashion. In the Fall of 2018, a team of two Library and Information Science graduate students, Kristina Bush and Claire Cahoon, and Nathan Kelber, the Digital Scholarship Specialist from the University Libraries at the University of North Carolina at Chapel Hill (UNC-Chapel Hill), formed an advisory council for the DHC-NC to create an interdisciplinary community focused on developing critical digital literacy skills by framing DH from a library perspective to emphasize research literacies rather than just tool competencies. To work toward this goal, the advisory council organized an ongoing series of local, small-scale educational events highlighting DH literacy, called “Institutes” as a nod to the Digital Humanities Research Institutes that inspired this project.
The 2019 Institutes focused on digital pedagogy, tools-based workshops, and networking.[1. In Spring 2019, Duke University hosted the first Triangle Digital Humanities Institute on DH Pedagogy. The second Institute, styled as an unconference, was hosted by the University of North Carolina at Chapel Hill (UNC-Chapel Hill) in the Summer of 2019. The third and most recent Institute was hosted in the Fall of 2019 by North Carolina Central University with the theme #RepresentationMatters.] Each Institute was hosted at a different institution in North Carolina and had a loose theme. The advisory council designed the Institute series to be choose-your-own-adventure in terms of organizing, scale, funding, programming, and staffing. While each institute incorporates themes of DH literacy, the focus of this article will be the Institute in the spring of 2019 because both authors were involved in and present at these events. In May 2019, with three council members and a small budget, we were able to pull off a three day unconference using our connections across the state of North Carolina to recruit instructors to teach tools and pedagogy workshops within their skillset. UNC-Chapel Hill has a wealth of expertise and resources (staff, hardware, and software) in the Digital Research Services Department of the University Libraries, which we drew upon in developing technical workshop content for the event.[pullquote]A major focus of each Institute was fostering a DH community by giving educators (faculty, staff, and even students) the opportunity to be a part of the scholarly conversation by sharing their work with colleagues from different disciplines and institutions.[/pullquote]
Each Institute’s theme embodied values described in Virginia Polytechnic Institute and State University (Virginia Tech) Library’s model of digital literacies. The Virginia Tech model identifies communication and collaboration as a core competency of digital literacies and aligns these skills with information literacy concepts such as source evaluation and participation in the scholarly conversation. A major focus of each Institute was fostering a DH community by giving educators (faculty, staff, and even students) the opportunity to be a part of the scholarly conversation by sharing their work with colleagues from different disciplines and institutions. Another aspect of the digital literacy model is creation and scholarship, which was addressed by teaching hard skills like Python or Tropy as well as holding pedagogy-focused sessions like “From Product to Process: Creating Student-Centered Learning Objectives for Digital Projects,” which focused on distilling student-centered learning objectives from tool-centric classroom projects. Another example of a digital literacies-focused workshop is “Teaching with Scalar,” which discussed using Scalar to allow students to creatively communicate and curate their research. Both of these workshops highlighted the importance of student-focused education to digital literacy. Virginia Tech’s definition of digital literacy puts the student at the center and encourages using media, data, and information literacies to become “engaged global citizens.” DHC-NC workshops teach instructors the skills necessary to use DH projects to empower students in developing digital literacy skills by moving beyond basic tool competency to engage in the scholarly conversation.
The talks and workshops at the Institutes taught participants that DH is more than knowing how to use a tool; it is about developing critical digital literacy skills. Models of digital literacy, including Belshaw’s 8 Elements, agree that collaboration and civic participation are key components of digital literacy. Belshaw defines the civic element of digital literacies as knowing one’s digital rights, responsibilities, and digital environments to participate in social processes and advocate for change online. Many participants came to the Institute with an idea in mind to give voice to historically-underrepresented communities through DH projects; unconference style discussions such as speed networking, birds-of-a-feather, and lightning talks connected these ideas with the tools and area specialists to develop projects. While technology proficiency is a core component of digital literacies, to be digitally fluent, we must also be mindful about how we use our technology of choice to communicate effectively and ethically in diverse digital environments. With this in mind, thoughtfully incorporating DH into the classroom through careful pairing of a tool with a project enriches a student’s critical engagement with course content. The Institutes create a space that applies critical pedagogy to teaching and learning tools, and encourages collaboration and civic-mindedness in our community.
Belshaw’s model of digital literacies includes the element “civic;” the spirit of civic-mindedness shapes the way the DHC-NC designs and plans Institutes. To invite a more diverse community of attendees to the summer 2019 Institute, the advisory board chose to delay registration to faculty and staff of R1 schools such as Duke University, North Carolina State University, and UNC-Chapel Hill. Large, well-funded institutions often offer professional development opportunities to their faculty and staff – we wanted to provide affordable and accessible DH training that transcended institutional boundaries. The Institute series brought together scholars from all disciplines and backgrounds to participate in a co-learning experience. There were even visiting international scholars![2. The scholars from Pakistan were participating in an exchange program organized by NCCU Professor Matthew Cook as part of the Duke-NCCU Digital Humanities Fellowship program. Read more about the program and the scholars here: https://sites.fhi.duke.edu/nccudhfellows/2019/10/08/connecting-north-carolina-and-pakistan-through-dh/] Being actively open and inclusive has allowed the network to grow, expanding our community from just the Research Triangle to the entire state of North Carolina, necessitating the recent name change to DHC-NC.[pullquote][W]e wanted to provide affordable and accessible DH training that transcended institutional boundaries.[/pullquote]
The 2019 series of Institutes allowed us to work with a variety of scholars, instructors, librarians, and students to practice holistic digital literacy, all while maintaining small scale and low cost events. The themes of pedagogy, tools, and representation highlighted digital literacy for our attendees in a way that facilitated critical thinking about DH. The DHC-NC’s collaborative approach to scholarship supports learning, engaging, participating, and building community through DH literacy. DHC-NC participants are invited to share their expertise and collaborate in order to build the DHC-NC community of practice centered on DH and digital literacy. If you’re in the North Carolina area, keep an eye out for future Institutes!
This past year an informal group of librarians began meeting to discuss the intricate relationships between digital humanities (DH) and literacies—information literacy, visual literacy, digital literacy, data literacy, and the like—with the intention of fostering a larger conversation around the topic and learn more about what’s actually happening “on the ground.” The group was motivated by the desire to help librarians striving to incorporate digital pedagogy into their teaching and those seeking to engage more critically with digital forms of scholarship. To contribute to this conversation, this dh+lib special issue is seeking submissions that explore DH work, be it research, digital project creation and evaluation, or digital pedagogy, through the lens of literacies.
The aim of this special issue is to provide readers from all areas of librarianship with greater insight into the intersection of DH and literacies, therefore, please keep the audience in mind and make choices such as defining DH-specific terms or linking out to resources that provide further explanation of DH methods and concepts.
New voices and submissions from graduate students, junior scholars, instructional technologists, and others who work on the frontlines of DH and literacy work are encouraged. Perspectives from outside of the U.S. are particularly welcome. Submissions may take the form of short essays (between 750 and 1500 words long) or responses in other media that are of comparable length. Possible topics include:
How can digital humanities tools/methods inform teaching information literacy concepts? Or vice versa?
How do aspects of the ACRL Framework for Information Literacy, such as the constructed and contextual nature of authority, fit in with digital humanities work? How do digital humanities methods and scholarship create challenges for the ACRL Framework?
How might the ACRL Framework (or other frameworks and literacies) serve as a basis for evaluating digital humanities scholarship?
What are the threshold concepts for digital humanities?
How might our professional literacies inform our collection practices, especially around collections as data?
How might DH literacies inform other areas of professional practice?
Conduct an analysis of a digital humanities project that explores the literacies and competencies necessary for its creation.
Discuss criticisms of literacies as a concept or issues with applying a literacy framework to DH work.
Please send your proposals in the form of a 250-word abstract and a brief biographical statement for each author to the editors at dhandlib.acrl@gmail.com using the subject line: 2019 Special Issue. Proposals are due by October 30, 2019.
The structure of digital humanities projects is often predicated on a manual or guidance document that supports project frameworks and outcomes. Heather F. Ball (St. John’s University), and Kate Simpson (IASH Fellow at Edinburgh University), as a librarian and literary historian respectively, have begun to explore the role of such documentation in the work of Livingstone Online and what that means for contemporary critical digital practice. In this post, they propose that these guides are both the crucial document by, and the site in, which knowledge is shared. Importantly, they suggest that such documentation can be used to facilitated subversive readings of historical nineteenth century European imperial hegemonic narratives.
Most digital humanities projects are production-based schemes. Their structure is often predicated on a manual or guidance document that explains how to produce, develop, and implement a part, or whole, of the project outcome. Such documents guide and shape the practice of the project, ensure quality control, and outline project procedures. More specifically within a transcription-based digital project, a coding or instruction manual is often used to ensure everyone applies the same rules to the texts, documents, or manuscripts being encoded. But these important project-shaping manuals can often take a backseat to the front-facing project outcomes and deliverables. What role do such documents play in the overall pedagogy of a project and are they as critically explored as the outcomes themselves?
As scholars, we have worked together for over eight years on Livingstone Online, a digital humanities project. The project captures and collates material created by and circulated to David Livingstone, a Scottish Victorian missionary, explorer, and expeditionary writer. Until recently, we gave little pedagogical thought to the tools that facilitated people whose areas of interest were 400 years apart – a medievalist and a postcolonialist – working effectively together. How do such, often dry and technical, documents enable creative engagement and production? We think these documents need greater analysis and engagement given how foundational they are to many digital humanities projects.
As a librarian and a literary historian our work has lately led us to shine a light on and examine the role of such documentation and what that means for our critical digital practice. We suggest that these guides are both the crucial document by, and the site in, which we share knowledge. They enable us to collaborate without having the same scholarly knowledge and thus our work engages with each other in the space in which the manual sits.
[pullquote][W]e are particularly interested in how our critical engagement with TEI-XML mark-up language, and in our coding behaviors, facilitates a model of digital archival practice which aims to actively subvert nineteenth century colonial and imperial ideologies of power and agency[/pullquote]
We want to explore how a medievalist librarian and a postcolonial literary historian can come together in the same medium, and how our work through the coding manual speaks to the larger conversation on interdisciplinary approaches to enriching the global nineteenth century corpus. Not only that, but we are particularly interested in how our critical engagement with TEI-XML mark-up language, and in our coding behaviors, facilitates a model of digital archival practice which aims to actively subvert nineteenth century colonial and imperial ideologies of power and agency. The following discussion will look at what we think is the role of digital humanities project documentation in critical pedagogy and practice. If you wish to explore the manual we will be talking about, it can be found at http://www.livingstoneonline.org/resources/livingstone-online-tei-p5-encoding-guidelines.
Livingstone is unique in his cross disciplinary interest; from scholars of exploration to colonialism, from anthropology to geography to African history to medical history, a rich cross-section of information and artifacts can be found within his works. His manuscripts show how scientific and political networks across the Victorian globe were set up and how the metropolitan center related to the imperial periphery. Through his writings in particular he not only documented his travels but, to paraphrase a journalist from 1876, he exploded the notion of Africa as a “howling wilderness”’ to British Victorian audiences.[1] These writings came in a wide variety of formats: diaries, field journals, notebooks, letters, missives, doodles, and jottings.
Given that so many of Livingstone’s writings survive – he is one of the most, if not the most, well recorded 19th century British explorer of Africa – they have an undue weight in the historical record, and as such it is not only important that we accurately encode and present the material but that we facilitate as many requests from the manuscripts as possible.
At Livingstone Online we have recorded over 3,000 Livingstone or Livingstone-related items – in 15,000 images and 780 transcriptions – so it is clear that we have made a lot of curatorial and editorial decisions in the creation of the digital library and museum. As more and more collections and archives are presented digitally it is especially important in our academic communities that those decisions are transparent and that best practice comes out of sharing and discussion. Particularly when that content has been gathered and managed via digital imaging, multispectral imaging, photography, TEI-XML encoding, Drupal, CSS, HTML and multiple other ways and is thus malleable in both its form and make-up.
The coding manual and me
Heather:
That malleability is even evident in our team. The Livingstone Online team began as a disparate band of academics headed by our Victorianist director (Dr. Adrian Wisnicki), each with our own areas of expertise from textual analysis and imaging scientists to medical historians and geographers. Over the course of multiple projects and grants, however, the intermingling of our individual knowledge became the collective corpus on which we built our work: our project’s coding manual. My work on Livingstone began with the multispectral imaging of several documents that had either been written as a palimpsest or whose text had faded due to ink Livingstone made on the fly with local plants or materials that didn’t stand the test of time. With multispectral imaging, a document is bathed in varying wavelengths, with each wavelength being captured as distinct files. They can then be examined individually or layered together so as to bring the indecipherable text forward for clear viewing. For Livingstone’s other works that were still readable, spectral imaging was not needed and standard capture methods were employed. Once the digital object was created, of paramount focus was ensuring we accurately represented the nuances of both the document text and artifact, digitally.
In the process of creating the digital object as an ultimately viewable representation on the computer screen, Livingstone Online uses TEI-XML markup to create elements, or tags, that identify information on the item as well as about the item. Elements are used to describe what is happening, such as where a line begins or what an item is, and they describe the structure, content and purpose of a document. They then have attributes within the tags that can further delineate details such as penmanship, authorship, foreign language, etc. Tags can be used to identify everything from date to distance, location to religion, a person to a spelling mistake, and an animal to a vegetable (tei-c.org).
My work as a cataloger informed how to encode the documents and enhance our practices and manual through structure, collation, and consistency within the TEI-XML framework. For example, a regular deletion code doesn’t notate if the text was crossed out singly, scratched out with multiple lines, written over inline, or crossed out with the correction written above. To be as true to the textual representation as possible, these distinctions were teased out and coded accordingly through custom TEI element and attribute creations.
TEI’s versatility helped us to play with their existing attributes, as well as add a few of our own. One thing that wasn’t obvious before a deep-dive into the transcriptions as a whole was that Livingstone covers not only a wide range of local plants, but foods, beverages, and rituals surrounding them. In order to more adequately capture that so that scholars could home in on all the plant life and food/beverages he documents, we added the attributes of plant_foodstuff and foodstuff to the TEI element “term”.
What began as a 10-page document meant to give coding guidance for Livingstone’s letters glacially morphed into a 488-page GitHub coding manual almost a decade later that accounts for his letters, field diaries, and the behemoth Unyanyembe Journal, which chronicled six years of his continental travel across almost 800 pages.
Though now a voluminous almost 500 pages, rest assured the manual is not intended to be read from start to finish – merely to be comprehensive coverage of any foreseeable circumstance one would need to code and how to drill right down to it. As one would use an encyclopedia, the coding manual is designed to be dipped into. Fairly early on the manual moved from being a .doc document to being held online by IT support at the University of Oxford, thanks to the work and support of James Cummings. This move made the document easier to navigate and negated the visual fear of being presented with a large technical document for our transcribers.
One of its most important features, in my opinion, is that the manual is a responsive, living document that transparently represents how our project has grown in our coding practices to fit the needs of both the text as well as the researchers now using them. By tagging such things as medical conditions, geographical features, weather patterns and rainfall, flora/fauna, animals/insects, and food/drink to name a few, we facilitate the use of Livingstone’s texts for many different disciplines and scholars.
Kate:
Using the coding manual as a historian initially has one brilliant benefit, and that is I don’t need another specialist’s or team member’s scholarly knowledge as well as my own. Our work and individual knowledge engages with each other in the space in which the manual also sits. As mentioned above, the manual becomes both the document by, and the site in, which we share knowledge. And in many ways my scholarship is strengthened by the iteration of using the manual as the frame over which I hang my scholarship. The encoding practices and patterns I use give me a tangible interaction with the documents, by recreating Livingstone’s journeys in code on the page I engage with them in a very critical and detailed way. My interaction with exploration through the manual happens, now that I’ve thought about the process, in a very specific way.
Firstly, I review: I fully engage with the text that is in front of me. A crucial slowed down analytical close reading process. The process of encoding creates a clear dialogue between myself and the text in which I can engage with both the remnant of the physical artefact and the digital object and its contents. It is at this point I separate the artefact from the content and begin to frame what I see in light of the questions the coding manual enables me to ask.
I then reparse: I look at the components of the line I am transcribing and I identify its elements. I read the sentence for the whole, but in the process of transcription I am really looking at the words, their order, content and meaning. In many ways my work at this point is like a context-sensitive highlighter pen. In my head the process is running along the lines of, “This is here and this is one of those, and I don’t have to remember where the other ‘those’ are because I know I can do these searches at a later date”. I don’t have to know what I am looking for or what I want to do with the information I find at the point I am transcribing, what I am instead doing is facilitating these future possibilities. This stage of the work also means in the true sense of reparse that anyone coming along in the future will be able to take the marked-up text and reparse that into whatever format they are using.
And thirdly, I reuse: although the coding manual avoids repetition, the physical iteration of transcribing and encoding, in some ways subliminally, teaches me as a literary scholar DH skills, in ways that theoretical coding might not be able to. Those who may be apprehensive about learning, or engaging in, a digital skillset may see such tools as too obtuse or difficult to relate to real world examples in the learning process. Personally I learnt to code in, and was confident in transcribing in, TEI-XML before I was aware that that was what I was doing.
This in some ways is the very essence of digital humanities. As Burdick et al note, “Digital Humanities is a production‐based endeavor in which theoretical issues get tested in the design of implementations, and implementations are loci of theoretical reflection and elaboration”.[2] It is the possibilities that such work creates in the conceptual design and critical encoding practices of digital repositories and libraries which serve to encourage reflective, disruptive and counter-consensus readings of intercultural encounter and the history of European exploration.[pullquote]It is the possibilities that such work creates in the conceptual design and critical encoding practices of digital repositories and libraries which serve to encourage reflective, disruptive and counter-consensus readings of intercultural encounter and the history of European exploration.[/pullquote]
Interdisciplinary communities of practice
Constructing a manual which facilitated interaction with disparate artifacts and was usable and effective for disparate scholars was arduous to say the least. But, ultimately it was the diversity of our team’s knowledge which enriched the manual, project, and our individual scholarship in ways not anticipated. One scholar’s knowledge of Scottish Gaelic, for example, informed another’s work when encoding foreign language tags; instead of coding “wersh” as an “undetermined” language or typo and its meaning potentially being buried, the interdisciplinary dialogue was able to retain its meaning (“bitter”) and illuminate the vitriolic context in which Livingstone was speaking. Elements like “tribe” and “nationality” quickly raised complex and controversial discussions that spanned coding practices, current interpretations, and implications contemporary to the time they were being used. This enabled not only an honest discourse over how certain terms propagate Victorian notions of representation and how we can challenge those notions through effective and transparent coding practices, but importantly a space in which these conversations could be had and documented.
Another interesting progression we had within the project was around nationalities. At first, the only coding the manual covered was African tribes, as that was what Livingstone seemed to speak on the most. Yet, in progressing through his texts, we found the interplay between African tribes and other nationalities, both on the continent as well as in Europe, very important. We expanded our coding to include nationalities such as English, French, and Portuguese. We also differentiated between the adjectival usages of nationality and added the attribute of people or person to denote the actual people. But what about those “nationalities” that weren’t linked to a specific tribe or country? Arab, European, and African were the terms that drove that discussion, and for which we chose to employ orgName. Seems straightforward enough, right? Not for a cataloger! OrgName is one of Heather’s favorite tags because with its utilization we moved past TEI’s original use for it relating solely to organizations, and tried to represent each group as honestly and transparently as possible, as well as be sensitive to the social and political issues certain tags (for example, “tribe” vs “people” vs “orgName”) incite.
These examples showcase different ways we have had to interact with the documentation and the choices we make in its creation. Subsequently, the purpose and the beauty of the coding manual is that for the user, these perspectives come together in a cohesive and well-informed representation of the page. Whilst at the same time, this evidences that within that self-same coding manual we attempt to make the configuration of knowledge horizontal, rather than hierarchical and so bound up with editorial judgements regarding “worth” of information.
Implications for critical pedagogy
The Livingstone Online coding manual was from the very beginning of our project an integral part in our project’s scholarly communication, advancement, and collaboration. Not only does our coding manual have pedagogical merit for other projects, it served to contemporaneously teach our team how to work together and share knowledge across disciplines in a unifying vernacular that everyone became well-versed in and channeled their expertise through: TEI-XML. Our coding manual is not some dry, required piece of notation, but a responsive, multi-faceted, and engaging document that drove our project and fortuitously engaged our team in past and current social issues.[pullquote]Not only does our coding manual have pedagogical merit for other projects, it served to contemporaneously teach our team how to work together and share knowledge across disciplines[/pullquote]
If we wish to facilitate translation, transnationalism and contextual variances in our understanding of history, it is the digitization of critical heritage which will enable a more complicated and ambiguous reading of the historical record. Fundamental to this process is ensuring that in the digital library, the recorded, reported and referenced voice of the ‘other’ is identified in, and reported out of, the sometimes-silencing strictures of nineteenth century imperial historical hegemony, publications and/or singular interpretations. This destabilizing of interpretations – particularly important in readings of nineteenth century colonial African exploration history – is pursuant on beginning to be able to identify the indirect traces of the power and agency of all peoples. Our digital practice has evolved to enable such traces of African peoples and their dealings with Livingstone to begin to be highlighted. Specifically, the opportunities presented to the user are enriched by using the TEI encoding to provide meaningful searches across content. For instance, TEI markup means that users can search for mentions of the same place throughout a corpus, even if that single place has been spelt different ways by multiple authors or if a single author has themselves spelt a single place a variety of ways. Livingstone’s multiple spellings of village names like Metaba, which he also spells Matawa, Mataba or Metawa, or of people’s names, such as Mponda also known as Mponde, can be followed across various texts. Thus, the encoding of the text is invaluable, enabling as it does the searching of what Marion Thain phrases as “words not in the text but intimately tied to it”.[3]
The translation of imperial power through the written word and the almost subversive turn that digital mediation of the manuscript enables means that users of Livingstone Online can access the primary records in part unrestricted by nineteenth-century value structures of what was useful, what was not, what constituted proper sources of knowledge, and what did not. Our interdisciplinary work in the creation of the coding manual has facilitated such subversive readings, providing a platform in which we shape and importantly evidence new structural frameworks of knowledge creation. In nineteenth century publications, the African person was often ‘othered,’ de-individualized, and made strange. The digital technologies and coding practices we adhere to at Livingstone Online are not only bringing these people forward within the data, they are allowing the record of exploration to be contested, critiqued, and challenged in ways that allow for new interpretations and readings; not only by us now, but by future users hopefully in ways even we have not yet seen.
[1] ‘The Transvaal’, 1876, p. 8 <https://doi.org/10.2307/60246804>.
[2] Anne Burdick and others, Digital Humanities (Massachusetts: The MIT Press, 2012), p. 13.
[3] Marion Thain, ‘Perspective: Digitizing the Diary – Experiments in Queer Encoding (A Retrospective and a Prospective)’, Journal of Victorian Culture, 2016, 226 (p. 233) <https://doi.org/10.1080/13555502.2016.1156014>.
Vicky Steeves is the Librarian for Research Data Management and Reproducibility at New York University – a dual appointment between NYU’s Division of Libraries and Center for Data Science. Vicky contributes to ReproZip, is a co-founder of LIS Scholarship Archive, and developed Women Working in Openness – an effort initiated by April Hathcock. Vicky holds a BS in Computer Science and an MS in Library and Information Science from Simmons College.
Thomas: I take it that you have a dual appointment in the libraries and an external center. Can you tell us more about your current work? Is your work novel? Might it suggest a model?
Vicky: Yes, I’m a dual appointment between the Libraries and the Center for Data Science. It’s exciting because I can flex my computer science muscles, working half time with the Center for Data Science supervised by one of the most badass women in computing around — Juliana Freire (first female chair of the Special Interest Group on the Management of Data for ACM). I contribute to tools like ReproZip that make an immediate impact on researchers. Working with Juliana, Remi Rampin, and Fernando Chirigati, I learn a lot about reproducibility with a particular emphasis on computational reproducibility (for an introduction check out Ben Marwick’s How Computers Broke Science). This work challenges me to think of scholarship more holistically, not just as an article and accompanying data, but as research materials and computational environment.
The other half of my time at NYU is spent building the libraries’ data management service with the wonderful Nicholas Wolf. We teach classes in the library and embedded classes for faculty upon request. We also build collections, create resources, and provide consultations for the NYU community. Nick and I only teach with freely available open source tools. This was a purposeful choice. We want students to be able to take what we teach them and be able to use it whether or not they are at NYU. We presented this model at the 2016 LITA forum.
I am certainly not the first librarian to have a dual appointment with an outside institute but I think the responsibilities of my job are novel. My job description explicitly requires me to support reproducibility initiatives. I receive a lot of questions from colleagues at other institutions about my role – my successes and failures. I wrote Reproducibility Librarianship, a “from the field” report, for Collaborative Librarianship that describes my day-to-day. The report is meant to be a resource for colleagues who want to fight for resources to support openness, reproducibility, and data management at their institutions. I think having well-resourced staff supporting reproducibility is important for enhancing and preserving the scholarly record.
Thomas: While you have a background in computer science and information science, I’d venture a guess that understanding of these areas doesn’t immediately resolve to some of your current areas of focus. Could you tell us about the path that took you to a career in libraries with this particular area of focus?
Vicky: I knew I wanted to be a librarian when I started college. I went into undergrad assuming I would major in English, thinking it was the best path into librarianship. Nanette Veilleux, my advisor, convinced me that I should take at least one Computer Science course, and that it might be more beneficial to librarianship than an English degree. I took one class with her, and I was hooked. The same professor approached me later that year and asked if I wanted to be “Student Zero” of the newly formed 3 + 1 program. This program would have me complete my Computer Science (CS) degree in three years, and my Library and Information Science (LIS) degree in one year. I jumped on the opportunity, as paying for college was tough. I had to work four jobs on top of school all four years, so I was grateful for the chance to pay less, finish up early, and get going in my chosen field.
After I finished up my LIS degree and started looking for work, I saw the National Digital Stewardship Residency (NDSR) opportunity on the Simmons job list. I thought it would be a valuable chance to get more hands-on experience with digital preservation. I applied to NDSR NY and got into my first pick host institution – the American Museum of Natural History.
This was my first run-in with research data. My project entailed interviewing all the curators and some of their staff and students to better understand their data storage, curation, and preservation needs. In the course of conducting these interviews I ended up answering questions from researchers like: “Why is the library doing this?”, “Isn’t this an IT job?”, and “What do you mean by data documentation?” In the course of answering I realized that I was explaining what archivists would call pre-custodial intervention — “acting to influence the arrangement, description, and appraisal of the materials by the creators before they are transferred to [a] repository” (Tatum 2010). Getting documentation together, migrating digital materials to open and preservable formats, making sure materials are stored and backed up securely. All of this was just digital preservation basics. I was explaining archiving and digital preservation to researchers and calling it research data management. It was a big lightbulb-over-the-head-moment for me. I took the results of these interviews and recommended strategies for preserving digital assets.
Thomas: Where do you think the Computer Science degree factors into your work, past and present, if at all?
Vicky: Well, I’d begin by highlighting the fact that very few librarians in the reproducibility and/or data management space have or need a computer science degree. For me, the most helpful part of my CS degree was the emphasis on learning how to learn technology instead of focusing on a few specific tools or programming languages. I’ve been able to adapt to different tools very well because of this and that has been immensely helpful.
My digital preservation classes introduced fundamental issues in managing and preserving all types of digital materials. The CS degree helped me understand the more technical aspects, e.g. how operating systems work, how file formats work, and so forth. I think computing or coding is seen as magical sometimes, and it’s really not.
My CS degree required two philosophy classes and one ethics class. These were huge in shaping my professional identity. Challenging and interesting questions were presented about privacy, sharing, and privilege that are important for any information professional. How are our systems privileging some users/patrons over others? How are we protecting user/patron data?
When I did my first degree, there were only two full time computer science professors at Simmons. I graduated with just 5 other people. We were a very tight-knit group. During graduation we all took The Pledge of the Computer Professional together and received this pin from the faculty which says ‘HONOR’ in ASCII:
It ended up being my second tattoo! The lines from the oath that have stuck with me are:
My work as a Computing Professional affects people’s lives, both now and into the future.
As a result, I bear moral and ethical responsibilities to society.
Thomas: Can you talk about a specific situation where your professional ethics came into play? As you thought about a way to work through that situation were there other people or examples of work that inspired you?
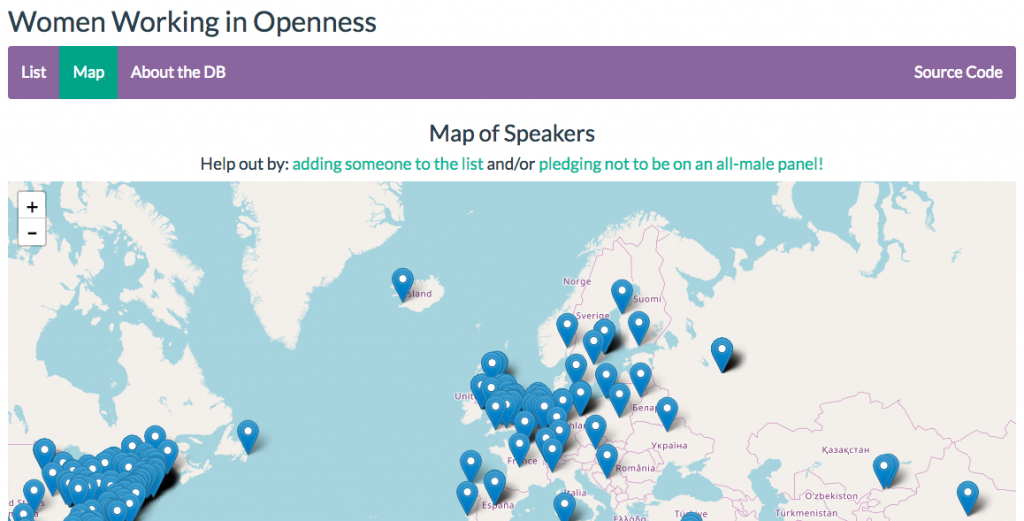
Vicky: It effects my day-to-day. How I approach building services, how I recommend resources to patrons, how I do my research, what I choose to spend time on. One side project I decided to work on was the Women Working in Openness site. The website itself is open source and uses CC0 self-reported data. It’s basically a searchable, sortable list of women who do work in the field of openness: open access, open science, open scholarship, open source code, open data, open education resources – anything open. The list started on April Hathcock’s google doc. I just transformed it into a list and a map on the web to encourage folks to quit it with the all-male panels on openness.
Women Working in Openness
When I started building services at NYU, I chose to only support freely available open source tools in my service area. This choice is guided by my ethics and is meant to help undermine lock-in with exorbitantly priced academic tools. Thinking back on The Pledge of the Computer Professional, this choice was made thinking about the students who come to my classes and workshops. Overwhelmingly I see graduate students and I really don’t think it’s right to train them on software that costs upwards of $200 for a standard license. Just because NYU has it isn’t a good enough reason. The students will leave someday, lose access (most likely), and have to learn something freely available anyway. It’s an ethical and an efficient choice to use FOSS tools.
I think a lot about the corporate capture of the scholarly record, and how my work in data management and reproducibility can either contribute to or disrupt that. With the rise of reproducibility as a buzzword, there are plenty of commercial entities ready to profit from so-called ‘reproducibility platforms’. This represents yet another corporate capture of scholarship. I try to disrupt this by advocating for community-run, open source software for reproducibility, such as ReproZip (which I work on), o2r, and Binder. The same goes for data management platforms. We’re seeing a lot of new data services springing up from major publishers and this is also something I am actively trying to combat.
Thomas: Lastly, whose work would you like people to know more about?
Vicky: In addition to all the folks I listed above:
Shirley Zhao, the Data Science Librarian at Eccles Health Sciences Library at the University of Utah is doing some excellent work around community building in data management and reproducibility. She’s currently running a course for librarians on data management and reproducibility via the National Library of Medicine. She also helps organize events like the Research Reproducibility Conference at the University of Utah, and short courses like Principles and Practices for Reproducible Science.
Cynthia Hudson-Vitale, the Data Services Coordinator and Research Transparency Librarian in Data & GIS Services at Washington University in St. Louis (WU) Libraries focuses her work on community infrastructure for scholarly communication and data curation. She is a part of the core SHARE team as well as the Data Curation Network. Her work in providing open, public-goods infrastructure will help keep the scholarly record in the hands of researchers.
As for other data or data-adjacent librarians, there’s too many to possibly name doing great work. I especially follow the work of Jenny Muilenburg at the University of Washington, Kristin Briney at University of Wisconsin, Amy Riegelman at the University of Minnesota, Renaine Julian at Florida State University, and Natalie Meyers at the University of Notre Dame & the Center for Open Science. But again, there are many folks doing excellent work around open infrastructure and databrarianship! I recommend readers follow the #datalibs hashtag on Twitter to find more of us and engage there.
As a digital humanities librarian, E. Leigh Bonds (The Ohio State University) undertook an institutional environmental scan as the basis for assessment, identifying gaps, and developing recommendations. In this post, Bonds details her approach and framework, which prompted conversations and coordination across campus.
In August 2016, I became The Ohio State University’s first Digital Humanities Librarian. I’d already been “the first” at another institution, so I was acutely aware that distinction is both a gift and a curse: on one hand, I have the opportunity to define the role; on the other, the responsibility of defining that role. More importantly, I knew “the first” typically has the task of mapping previously uncharted (or partially charted) territory—the scope of digital humanities on campus—and exactly one week into my new position, I received that first charge: conduct an environmental scan of DH at OSU.
Having never conducted a formal environmental scan before (or even witnessed someone else doing one), I turned to the literature: no one charged with such an undertaking—regardless of campus size—does so without consulting those who have already charted their own environments. From recent publications (see Works Consulted), I gleaned that the scan should determine the nature of DH work underway, researchers’ interests, researchers’ needs, existing resources, and gaps in resources. All of the information gathered would then be complied into a report—in my case, an internal report for the Libraries’ administration and the head of the research services department—that included recommendations based on the findings.
[pullquote]Environmental scans should determine the nature of DH work underway, researchers’ interests, researchers’ needs, existing resources, and gaps in resources.[/pullquote]
What follows is my strategy for making these determinations and framing my report. Rather than provide a one-size-fits-all template (which would most likely work for no one), I explain the process I followed—and the thinking behind that process—to guide other “firsts.”
Identifying Key Researchers
Determining who was doing DH and who was supporting that work seemed the logical place to start. I spent the first week scanning the twenty-three humanities and arts departments’ web pages, skimming every faculty page, and noting the names of those I needed to meet and the work they were doing or supporting. Unfortunately, very few identified with “digital humanities,” so I found myself delving into CVs, looking for DH-related keywords in publications and presentations (network, data, mapping, visualization, computational, digital archive, etc.).[1. Several months after my initial scan of faculty pages, I participated in the University of Illinois iSchool Spring Break Program and guided three MLIS students—Brett Fujioka, Tanner Lewey, and Abby Pennington—through a second scan of humanities faculty pages and CVs to identify faculty either using DH methods and tools or with research interests that lend themselves to their use.]
To validate my findings, I next met with the subject librarians for each of these departments. I shared the findings from my “distant scan”; they gave me further information about what I’d found and, in a few cases, about what I hadn’t found. Additionally, these meetings gave me the opportunity to talk with my new colleagues about DH and my role, and to gauge their understandings, interests, and experiences with DH work.
In the subsequent months, I met with the majority of the faculty on my list. I asked them about their interests, experiences, and ideas for both their research and for integrating digital humanities methods and tools into their courses; the resources they have and those they lack; their graduate students interested in this work; and about what they envision for DH on campus. From these conversations, I learned about the various digital methods and tools being used, and the resources available and still needed on campus. I also learned about the initiatives faculty had undertaken prior to my arrival on campus, like establishing a working group and proposing an undergraduate minor.
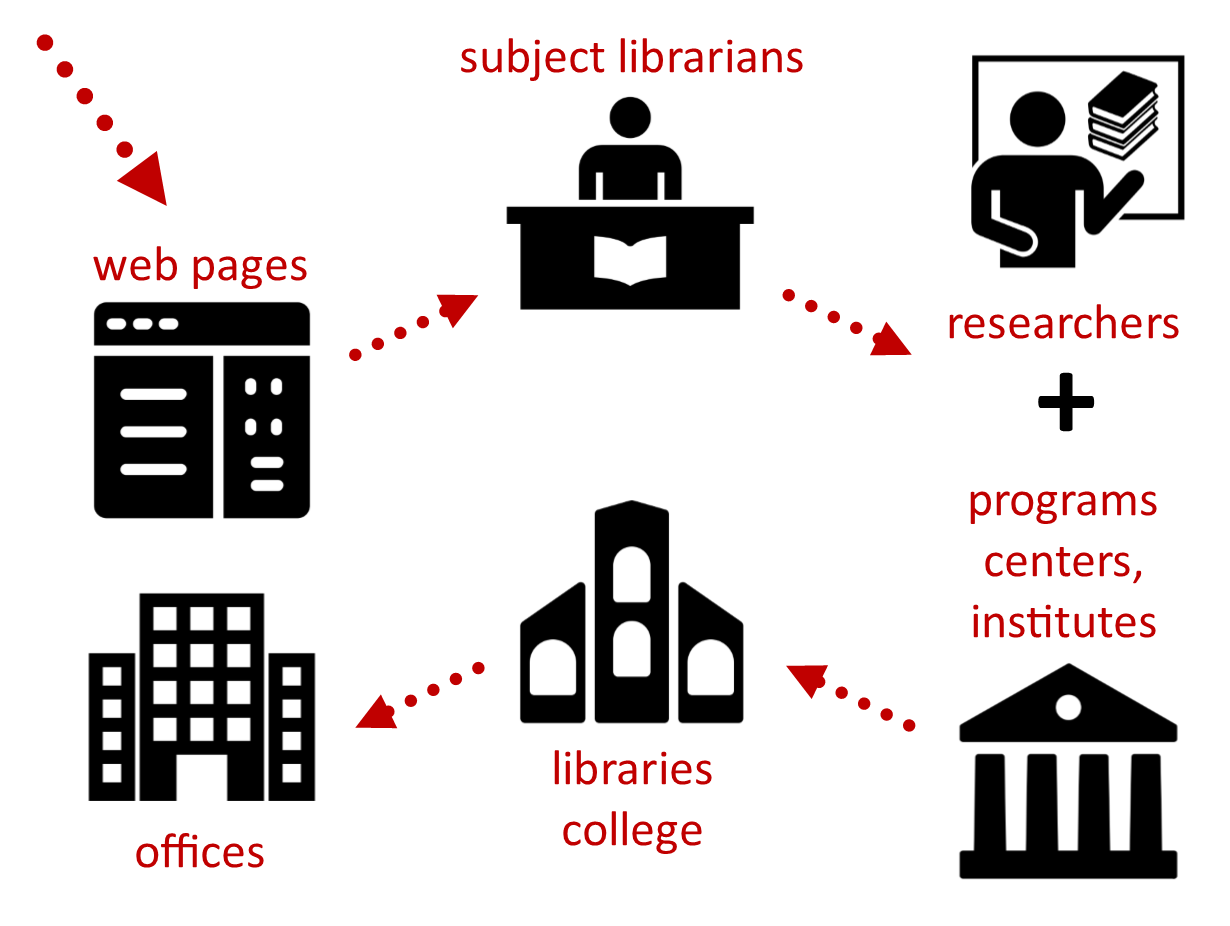
In addition, I scheduled appointments with the directors of the humanities- and arts-related programs, centers, and institutes on campus with affiliated faculty doing DH work. During these meetings, I asked them many of the same questions I asked the faculty, but I focused more on the forms of support they provide and the resources they have available for humanities research.
As I met with the key researchers, I also began meeting with faculty and staff in several support units across campus. Within the Libraries, I found several staff supporting digital research projects in a variety of capacities: special collections, archives, digital imaging, digital initiatives, copyright, metadata, acquisitions, and application development. In meetings with each, we discussed their involvement in this work thus far, interests in continued involvement, and resources. In the College of Arts and Sciences Technology Services, I met with three department heads to learn more about the research consulting (computation and data storage), academic technology (media and eLearning resources), and application development services. From them, I learned the specifics of the services offered, who in the humanities and arts were using their services, the types of projects they’d been involved in, and, in the case of application development, what costs were involved. In the Office of Research, I met with the development specialist to discuss funding opportunities for DH work and a research integrity officer to discuss university policies governing intellectual property and data ownership. Not only was it important for me to learn about these matters myself, it was also important to learn to whom to send faculty to discuss funding opportunities and intellectual property matters as they arise.
Defining DH
[pullquote]I was less interested in labeling than I was in learning what researchers were doing or wanted to do, and what support they needed to do it. Ultimately, I viewed the environmental scan as the first step towards coordinating a community for researchers with DH interests.[/pullquote]At some point in nearly all of my conversations, the question “What is digital humanities?” was inevitably asked. Rather than tell, I preferred to show, so I explained DH in terms of the range of work being done by researchers across humanities and arts disciplines. I also clarified that, for the purposes of my environmental scan, I was less interested in labeling than I was in learning what researchers were doing or wanted to do, and what support they needed to do it. Ultimately, I viewed the environmental scan as the first step towards coordinating a community for researchers with DH interests.[2. Approaching DH from “the liminal position” of the Libraries, outside “of discipline or department,” as described by Patrik Svensson, I adopted the view of “the digital humanities as a meeting place, innovation hub, or trading zone,” which I see as essential for building the community I envision.]
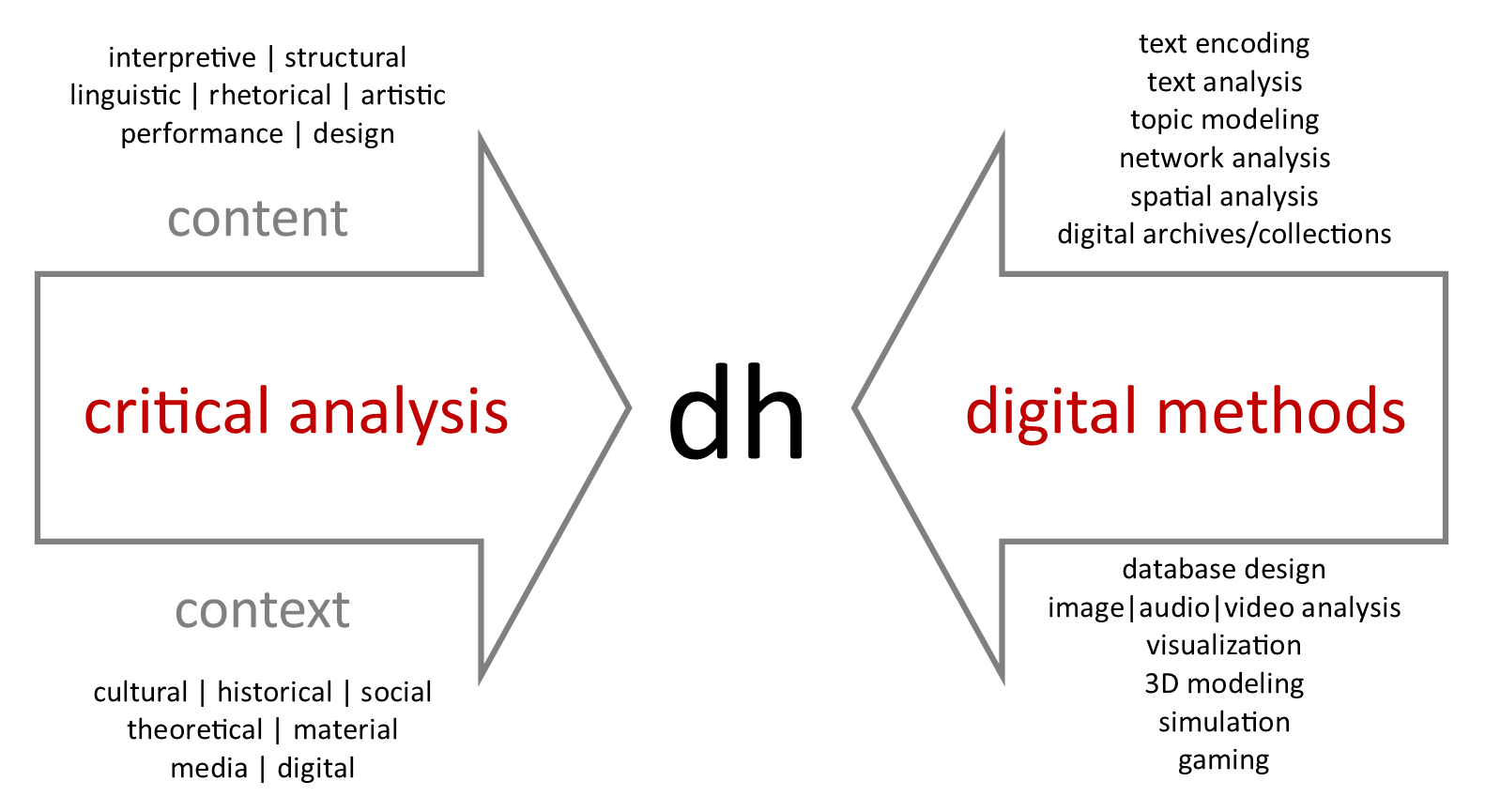
For the report itself, however, I realized I had to tell in addition to show. To reflect “the breadth of DH work being produced at OSU,” I defined the digital humanities simply as “the application of digital or computational methods to humanities research.” I explained it “involves both the interpretive, critical analysis skills developed through humanities study and the technical skills required by the digital/computational method.” “For this reason,” I added, “digital humanities projects are often collaborative with each collaborator contributing a different skillset required by the critical or digital aspects of project.” I created a simple graphic to show “the extent of humanities analysis of content and context, and the variety of digital and computational methods currently being employed to conduct and/or disseminate that analysis.”
Digital Humanities Praxis
As Alan Liu remarked about his “Map of the Digital Humanities,” I never intended this to be “the last word.” Instead, I wanted it to be a catalyst for continuing conversations on our campus.
Tracking DH
Likewise, I wanted the history of DH on campus to raise awareness that researchers had been “doing DH” for quite some time—without an institute, center, program, or other form of structured support. For this section of the report, I opted to show rather than tell.
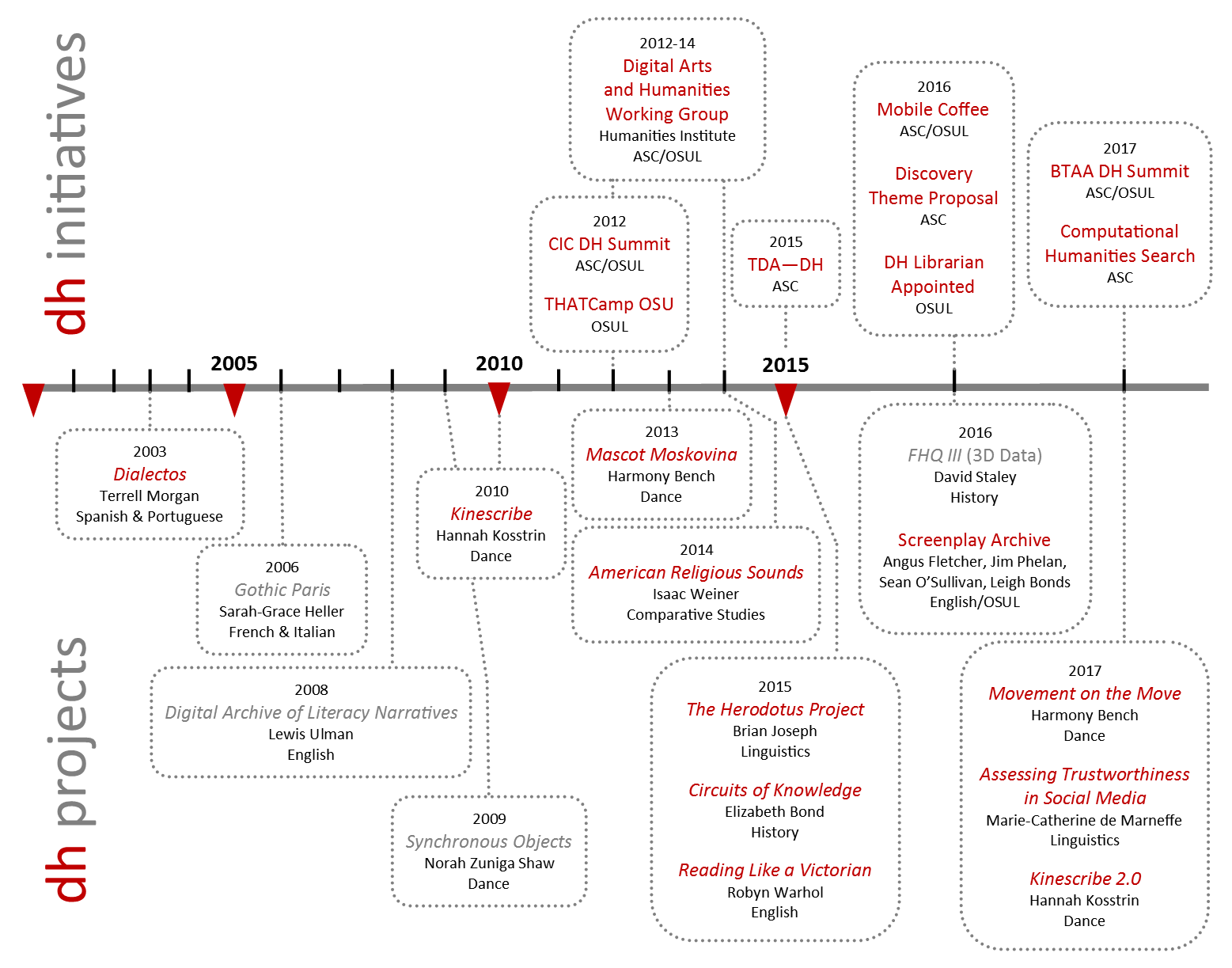
Overview of DH Initiatives and Projects
Admittedly, this timeline of initiatives and projects was not comprehensive; it did, however, reflect the key points that DH had been on campus since the early 2000s and the projects are increasing both in number and in complexity.
Framing the Report
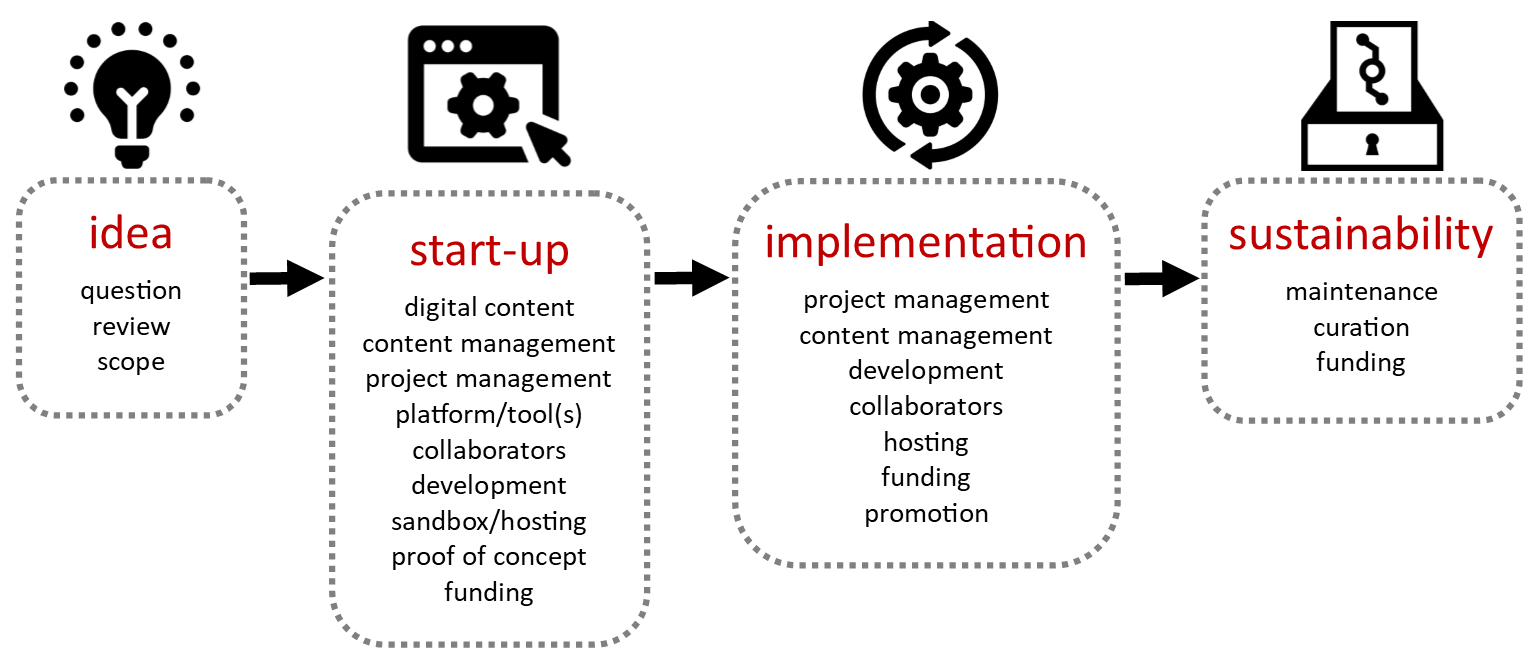
As I began thinking of how to structure the report, I realized I needed a framework—and a clear set of terms—for discussing project requirements. Using the phases outlined by the National Endowment for the Humanities Office of Digital Humanities, I created a DH project lifecycle graphic to provide that framework:
And in the report, I explained the specific support and resource requirements for each stage, including consultations with experts in digital methods, content/project management, platforms/tools, and funding.
Existing Support & Resources
[pullquote]I wanted the history of DH on campus to raise awareness that researchers had been “doing DH” for quite some time—without an institute, center, program, or other form of structured support.[/pullquote]That framework then provided the structure for the subsequent discussion of existing support and resources related to specific project requirements:
digital content
content management and project management
DH methods, platforms, and tools
development, hosting, and curation
In each of these sections, I outlined who provides the support/resources on campus and off-site, the specific support/resources available on campus and off-site, whether costs are involved, and any conditions that apply to the support/resources.
The section about digital content focused on three common forms: content in older formats requiring digitization, content existing in digital formats, and content generated by the project. I listed the specific sources for each content form (e.g. researcher, collaborator(s), OSU Libraries, external libraries/museums, vendors, work for hire), and indicated whether any costs are involved or whether any conditions apply (e.g. limited format types, limited permissions). Due to the costs involved, I differentiated work for hire (e.g. students, staff, external services) from collaborator(s) as a source.
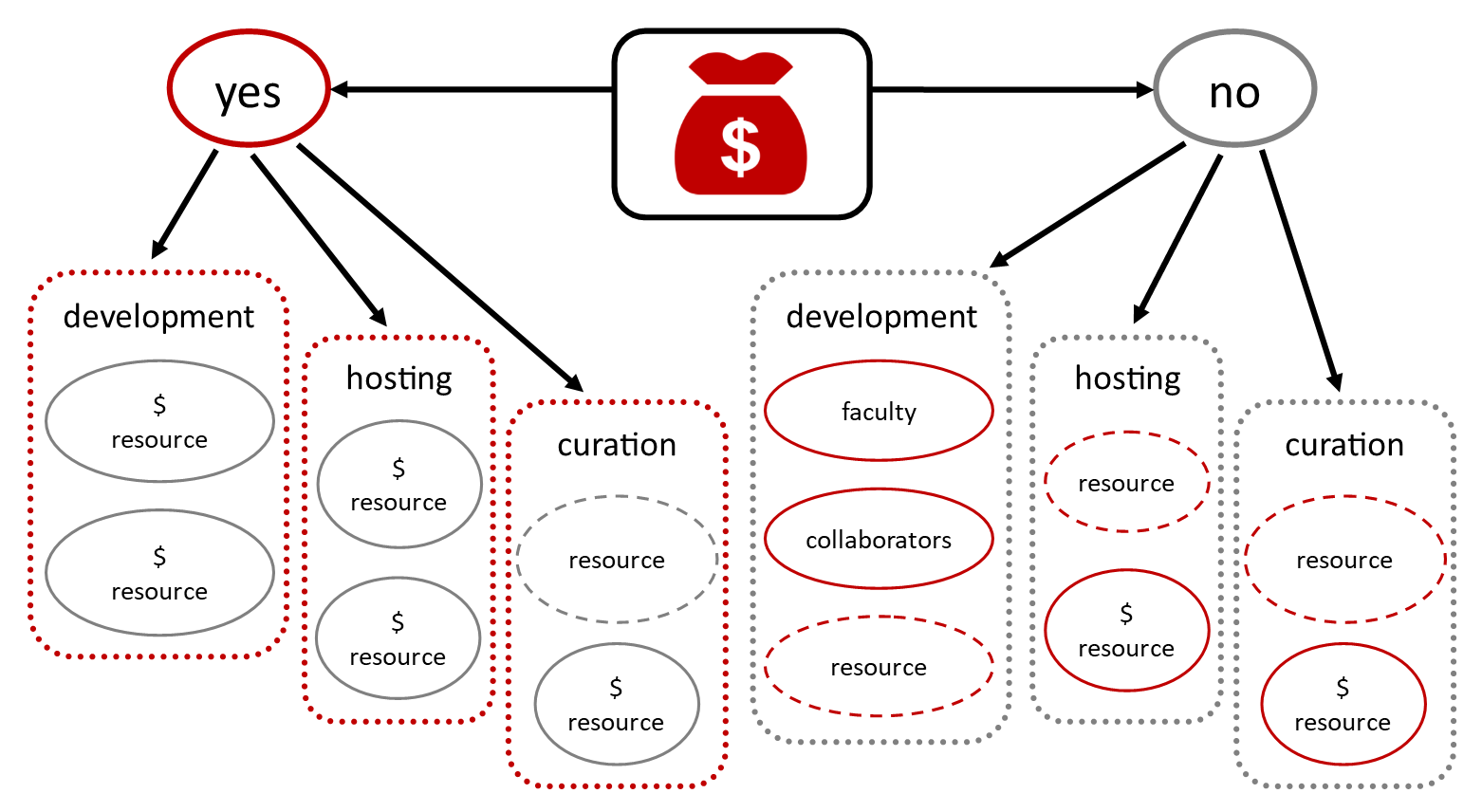
The discussion in the development, hosting, and curation section was further divided by whether a project has funding or not. In the infographic included in my report, the specific units on campus providing support in these areas were listed, and off-site was included as a resource option for hosting and curation. Again, I differentiated work for hire from collaborator(s) for cost reasons.
Existing Support and Resources. (Icon from The Noun Project: “Fund” by OCHA Visual Information Unit.)
To highlight gaps, it was important to emphasize that some of the resources remain conditional (indicated by a dashed outline) even when a project is funded and some of the resources involve costs (indicated by the dollar sign) even when a project is not funded.
Surveying Key Researchers
Finally, I invited thirty-eight faculty identified during the scan to complete a survey about their experiences developing a DH project and about their needs (and the needs of their graduate students).[3. Ithaka S+R “Sustainability Implementation Toolkit” survey by Nancy Maron and Sarah Pickle guided the one I developed, particularly for the questions related to the support received for digital projects.] I asked those who’d developed a project to rate the level of support they received for specific stages of the project lifecycle—from refining project scope to development to maintenance—and to identify which units on campus provided that support. I asked about funding, collaborators, external support, and work for hire for past and current projects; and I asked everyone what support they would need to develop a future project. The twenty responses I received—a 52.6 response rate—validated and further supported the findings from my conversations.
Additionally, I asked what workshops/sessions would interest them and their grad students, grouping the possibilities into three categories:
best practices—like project management and content/data management
DH methods—like data scraping, spatial analysis, visualization
These categories reflect the scaffolding I envision for DH programming with different sessions, workshops, and working groups building upon one another and becoming increasingly more specialized and project-specific.
Identifying Gaps & Making Recommendations
All of the information I gathered during my first eight months at OSU exposed seven foundational gaps related to infrastructure, development/design support, and learning opportunities. Of course, anyone reading the report could have surmised the list themselves: I’d pinpointed the project requirements for each stage, reviewed the existing support and resources, and conducted a survey of researchers using DH methods and tools (the results of which were included in an appendix).
As a result, the recommendations in the concluding “Future Directions” section prioritized addressing the gaps in the infrastructure—on which the majority of future initiatives rely—followed by providing learning opportunities for faculty and graduate students. I subdivided the section into recommendations for my role as the Digital Humanities Librarian; for the Research Commons as the research hub; for the Libraries as both DH producers and supporters; for a partnership between the Libraries and the College of Arts and Sciences; and for consortial partnerships. In making the recommendations, I took capacity and scalability into account, knowing that many of the infrastructural gaps—as well as researchers’ desires for academic programs and centralized support—could not be remedied by the Libraries alone. For the purposes of these recommendations, whether the Libraries or the College could or would meet these needs or fulfill researchers’ desires didn’t matter: I simply identified them as areas to address.
To show what others in the Big Ten Academic Alliance and other R1 institutions with established DH programs were doing, I included a spreadsheet in an appendix indicating whether, for these institutions:
there is a DH center on campus
the DH center is a partnership between the college and the library
the library has its own center
there is an undergraduate minor
there are other undergraduate programs
there is a graduate certificate program
the campus is a Digital Humanities Summer Institute (DHSI) institutional partner
the campus is a Reclaim Hosting Domain of One’s Own Institution
Not only did the spreadsheet provide a quick point of reference for who’s doing what, it also provided administrators with points of contact for further investigation.
Following Up
[pullquote]Rather than the culmination, the report was, in fact, the beginning—the first iteration in the environmental scanning process that will continue both formally and informally.[/pullquote]In May, I submitted my environmental scan report to the head of the research services department, who submitted it to the associate directors and the director. Over the course of the summer, the report was dispersed more widely within the Libraries, sparking a number of important conversations about workflows, scope, and scalable support structures. In addition, it directly informed the planning for workshops, learning sessions, and working groups through the Research Commons.
In the fall, conversations across campus ensued as I shared my environmental scan with faculty, institute/center/program directors, and technology services directors. In addition to partnering with colleagues to teach sessions on the top areas of interest identified by the survey, I held a “DH Forum” for faculty and graduate students to review the key findings in my environmental scan and “discuss ideas for advancing the digital humanities at OSU.”
As administrators and deans discuss funding and partnerships in the coming months, I’ll be consulting with researchers, collaborating on projects, and coordinating the DH program. Each of these points of contact provides opportunities to continue environmental scanning, to expand the campus support network, and to establish the community of researchers. Rather than the culmination, the report was, in fact, the beginning—the first iteration in the environmental scanning process that will continue both formally and informally for the remainder of my time as the first.
The dh+lib site debuted at the Digital Library Federation Forum in November 2012. As we approach the five-year anniversary of this project, we thought we should take a moment to reflect on where we’ve been and where we’re going. Sarah and Roxanne are the founding editors of dh+lib and, along with Zach Coble (who joined just a few months in), have been steering the project since its inception, aided by the collaborative efforts of Patrick Williams, John Russell, Caitlin Christian-Lamb, Sarah Melton, Nickoal Eichmann-Kalwara, Thomas Padilla, Caro Pinto, and Josh Honn.
How it got started
The dh+lib project was born out of a listerv. More specifically, it was a desire to break out of the library listserv bubble.
In 2011, members of the Association of College & Research Libraries (ACRL) Literatures in English Section began to circulate a petition to form a Digital Humanities Discussion Group within ACRL. (According to ACRL, discussion groups are typically experimental, and are designed to do just that: discuss.) By the fall of that year, the discussion group was approved, with Kate Brooks and Angela Courtney as conveners, and the accompanying email list was created. While messages about DH and libraries began to trickle in, things really heated up when Bob Kosovsky shared a call for panelists from the Theatre Library Association on “Digital Humanities and the Performing Arts,” noting that many of the questions were worth addressing more generally—outside of the performing arts context. In typical fashion, Micah Vandegrift replied with a provocation:
“I think it’s time to be more assertive about the librarian as co-equal, co-creator, collaborator, co-PI, integral to the entirety of the digital humanities process, from grant-writing to project development and management, to preservation and maintenance of the products/objects.”
This set off a flurry of messages, including one from Roxanne Shirazi, who suggested that if we were to bring librarians to the center of the digital humanities discussion we should take our discussion off a listserv and make it public. Soon, plans for a group blog were taking shape. Brooks and Courtney found that ALA could provide a WordPress installation for the group, while Shirazi had connected with Sarah Potvin, who’d volunteered on the list, to scope out a project separately. Within weeks, the two pairs had combined efforts, and dh+lib was born.
Only it wasn’t called dh+lib just yet. While we worked to survey our group for input on just what kind of site we should make, the project itself remained nameless. [pullquote]Note to future project creators: name your site in such a way that people know how to pronounce it.[/pullquote]Following the trends of the time, the leading contender was “DH @ Lib” but that soon became “dh & lib”—until a simple design choice changed it to “dh+lib,” with the tagline: “where the digital humanities and librarianship meet.” The plus sign was intended to be read as “and,” with the hopes that it would visually indicate a crossroads, or meeting place. (Note to future project creators: name your site in such a way that people know how to pronounce it.)
The ACRL group had its first business meeting in the summer of 2012 at the ALA Annual Conference in Anaheim, California. Those in attendance at that meeting will remember the scene: a smallish conference room in a far-flung ALA hotel, a continuous stream of chairs unstacked and occupied as more and more people arrived. A portion of the meeting was devoted to discussing the direction of the group blog (for a full recap, see Bob Kosovsky’s notes). Many pointed to ProfHacker, Hack Library School, and Digital Humanities Now as models to follow. Zach Coble was in attendance, and had recently participated in a PressForward workshop at THATCamp Prime. Zach offered to help build an RSS-driven aggregator for the blog, and joined Sarah and Roxanne as project developers.
For the next few months, Sarah, Roxanne, and Zach moved forward with testing out blog themes, crowdsourcing rss feeds, compiling resources, and inviting contributors. Meanwhile, Angela Courtney was scheduled to appear on a panel at the Digital Library Federation Forum in Denver, and was one of the organizers of a Digital Humanities & Libraries THATCamp preconference. We decided that would be a good time to unveil the new site. DLF also seemed like a natural fit for launching the project, signaling our intentions to serve a community beyond ALA/ACRL.
An online publication is the core of dh+lib, but, given our goals of facilitating conversation, exchange, and a community of practice, the project also extends offline, primarily at conferences, where editors have hosted meet-ups, workshops, and THATCamp sessions, participated in panels or given posters. Hundreds of dh+libbers have sipped drinks or balanced pizza slices at events held at Digital Humanities, the Digital Humanities Summer Institute, the Digital Library Federation Forum, the Society of American Archivists annual meetings, and the American Library Association Annual and Midwinter meetings.
Building a community of practice
How do you start a site, a project, a community and develop it from an idea on a listserv into something that people list on their CVs, dedicate their time to, affiliate with? Not without the championing and support of many. The ACRL group cultivated the project unjealously, dedicating time and resources to it while supporting its independence. The first conveners, Angela Courtney and Kate Brooks, were instrumental, and, as the DH Discussion Group became the DH Interest Group in 2014, we collaborated with conveners Zach Coble, Krista White, Thomas Padilla, Harriett Green, and Hannah Scates Kettler. Alix Keener and Chelcie Juliet Rowell, the DHIG’s final conveners, and Brianna Marshall, chair of the newly-formed Digital Scholarship Section (DSS), have conscientiously guided the project through the DHIG’s merger into the DSS.
As young upstarts, we were encouraged and advised by luminaries in the field. Most strikingly, these key figures—including Michelle Dalmau, Harriett Green, Trevor Muñoz, Lisa Spiro, Stewart Varner, and many many others—volunteered as editors-at-large and wrote posts. Editors at In the Library with the Lead Pipe and DHNow either advised directly or helpfully shared documentation that guided our early workflows. The team at PressForward has been unfailing in their willingness to collaborate and adapt Review workflows: thanks are due to Lisa Marie Rhody, Joan Fragaszy Troyano, and Stephanie Westcott.
Over the past five years, more groups and organizations have formally ventured into digital humanities and libraries, providing us with opportunities to join forces and to move beyond the North American context.[pullquote]In 2013, a Libraries and Digital Humanities Special Interest Group was formed under the ADHO umbrella … balancing out our DH-in-libraries affiliation with an international libraries-in-DH scope.[/pullquote] In 2013, as dh+lib was just getting started, a Libraries and Digital Humanities Special Interest Group formed under the umbrella of the Alliance of Digital Humanities Organizations (ADHO), convened by Zoe Borovsky, Glen Worthey, Angela Courtney, and Sarah Potvin. That convener group, which grew to include Isabel Galina Russell, Thomas Stäcker, Hege Stensrud Høsøien, and Stefanie Gehrke, has provided a second institutional home for dh+lib, balancing out our DH-in-libraries affiliation with an international libraries-in-DH scope.
In this vein, dh+lib has begun to focus on building a more inclusive and international community around digital humanities and libraries. One of our targeted areas is translation, as a means of increasing the recognition of non-Anglophone digital humanities work among our English-speaking audiences. In collaboration with RedHD, the network of digital humanists based in Mexico, we worked to simultaneously publish English and Spanish versions of an essay on self-representation and geopolitics in DH. With support from ADHO’s Global Outlook::Digital Humanities and Libraries and DH special interest groups, we are currently pursuing growth that will allow us to identify relevant scholarly work in languages other than English and circulate it to our community of practice.
dh+lib has been sustained, enlivened, and strengthened by its contributors—editors, authors, editors-at-large. Every week, the site grows by the contributions of our volunteer editors-at-large, who have nominated relevant research, resources, calls for papers, and other items of interest or written up what they’re reading. Our talented editors—Patrick Williams, John Russell, Caitlin Christian-Lamb, Sarah Melton, Nickoal Eichmann-Kalwara, Thomas Padilla, Caro Pinto, and Josh Honn—have devoted countless hours towards a community goal. As our team has grown over the years, we have stayed true to our collaborative ethos, while recognizing that we are all volunteers in this publishing experiment. We communicate frequently, but informally, relying on the give and take that happens when a group of dedicated individuals are working across institutions and time zones while navigating the competing demands of our personal and professional obligations. One of the challenges of institutionalizing the project has been the difficulty in setting clear roles and dividing lines between a team of generous editors who move fluidly between responsibilities, picking up where another has left off.
Looking ahead
It’s a funny exercise, as an editor or a project founder, to look at a project for what it is, what it has produced or influenced. Our view is often obscured by all the things that might have been—the series or efforts that have stalled, the collaborations we always intended to pursue, the posts still in editorial limbo, the projects we always wished we had more time for.
As we’ve approached the five-year launch anniversary, all of the abstract conversations we’d had about succession planning and governance coalesced into something more concrete. Sitting with Zach at a coffeeshop up the street from Bobst Library in April, we found ourselves all in agreement: it was time to transition the project to new editors. In many ways, the timing was right: the ACRL Digital Humanities Interest Group was being absorbed into a new Digital Scholarship Section, spurring questions of affiliation and ownership. The landscape of dh and libraries had shifted significantly since 2012, and we wondered: approaching this area today, what would we design to forge, to serve, this community? Have we filled the need we set out to fill?
The question of where and how the digital humanities and librarianship meet is one that still drives us today. And while it may be time for the founding editors to move on, we’re not leaving just yet! At this moment of opportunity, the dh+lib editorial team has begun discussing new governance structures and working out scenarios for strenthening the organizational and community ties we’ve established along the way. As part of that process, we’re going to spend more time documenting what we’ve done and compiling data that can be used to guide these decisions for the future (and sharing that data more widely, in the interest of transparency as well). We hope that this post on our history was a useful start to that process.
Last June, a group of librarians, technologists, and scholars met at Middlebury College in Vermont to think about how to move forward on a proposed network, the Digital Liberal Arts Exchange, that would support digital humanities scholarship and teaching across institutional boundaries. There was much discussion, as we looked out over the Green Mountains on a perfect early summer day, of the particular stresses on library infrastructure when it came to supporting, leading, and engaging with digital projects, in contrast to how libraries support traditional humanities scholarship. At one point, someone noted that the conversation was drifting back toward the tired dichotomy of “hack” and “yack”–that is, DH as coding and making things versus DH as critique of digital culture. I suggested that we might think about a third term–“stack”: the often invisible technological, social, and physical structures within which scholarship is produced and disseminated. Since that meeting, I’ve been considering different concepts of “stack” in relationship to DH as models for these structures of labor. I’ve also found myself having more and more conversations–at work, at conferences, on social media–about how exposing DH infrastructure (in terms of how it supports both making/”hack” and thinking/”yack”) can reveal the conditions that make all kinds of scholarship possible.
In this post, I would like to “browse” the DH stack through three different frames: first, the technology stack of globalized computing; second, the social stack that manifests as institutional infrastructure; and finally, the physical library stacks that are a synecdoche for the information architecture that arranges scholarship. I’m curious to explore what these three frames–technological, social, and physical–could offer in terms of different ways to understand and reveal DH labor in the academy. My thoughts here build upon both Shannon Mattern’s idea of library as infrastructure and David Weinberger’s idea of library as platform. Rather than thinking of the library itself as an infrastructure, platform, or stack, I would like to consider what–and who–these concepts hide. As I’ve observed elsewhere, the people who “hack” and “yack” can’t work without the people in the “stack” (or without the people in the library stacks). At a time of political crisis, when the core values of libraries and access to knowledge are being challenged, we need to take responsibility for showing what we do. DH librarians, whose highly collaborative work is dedicated to social justice and public engagement, may be one particularly vital community of practice for exposing the changing conditions that create knowledge. How do we make labor in the “stack” visible?
Benjamin Bratton, in The Stack: On Software and Sovereignty (MIT, 2015), suggests that we think of the vertically integrated organization of global computing as a more pervasive version of the software stack, whereby a web application, like the WordPress platform for this blog, runs on top of a database that runs on top of an operating system (which runs on top of the hardware). Bratton’s global Stack is totalizing: it rises from raw materials mining at the bottom to hardware manufacture as the next layer, and thence upward from network infrastructure to web programming to user interface design to tech support. It has emerged as “an accidental megastructure, one that we are building both deliberately and unwittingly and is in turn building us in its own image.”[1. Benjamin Bratton, The Stack: On Software and Sovereignty (Cambridge: MIT, 2015), 5.] This is the megastructure of globalization, whereby computing networks transcend and surpass national boundaries and identities. The Stack is not just a new technology, but operates as “a scale of technology that comes to absorb functions of the state and the work of governance” (kind of like the Matrix).[2. Bratton, The Stack, 7.] What Bratton calls the Stack as megastructure also shapes (and perhaps defines) the globalized university, in that basic internal services, such as communication, record keeping, and financial management have been outsourced to cloud-based enterprise systems. In turn, research libraries within this megastructure operate in an economy that deemphasizes (and sometimes discards) ownership of local collections in favor of access to licensed resources that are facilitated by institutional relationships with multinational corporations. Yet–like the fish who asks “what is water?”–most scholars are unaware of the extent to which their work, professional interactions, and finances are imbricated with the global technology Stack.
How does DH fit within this megastructure? According to some critics, DH is part of the problem of the neoliberal university because it privileges networked, collaborative scholarship over individual production. If creating a tool (hacking) or using computational methods has the same scholarly significance as writing a monograph, then individualized knowledge pursued for its own sake, the struggle at the heart of humanistic inquiry, is devalued. Yet writing a book always depended on invisible (gendered) laborin the academy. Word processing, library automation, and widespread digitization are just three examples of the support labor for traditional scholarly work that Bratton’s globalized technology Stack has absorbed. (And we know that the fruits of that labor are in no way distributed equitably.) What has changed in the neoliberal university is that the humanities scholar becomes one more node in a knowledge-producing system. Does it matter, then, whether DH work produces ideas or things, critics say, if all are absorbed into a totalizing system that elides the individual scholar’s privileged position? This is of course a vision of scholarship that is traditionally specific to the humanities; lab science and the performing arts, for example, have always been deeply collaborative (but with their own systems of privilege and credit).
The Social Stack
If Bratton’s Stack is characterized by a globalizing rationality, the social infrastructure of the university is highly irrational, as Alan Liu discusses. What Liu calls the field of “critical infrastructure studies” could “’see through’ the supposed rationality of organizations and their supporting infrastructures to the fact that they are indeed social institutions with all the irrationality that implies.” Institutional arrangements of DH are often social and contingent (in the very concrete sense that many who work in DH–graduate students, postdocs, people in grant-funded term positions–are classified as contingent labor). Many DH programs, initiatives, and teams have arisen organically out of social connections rather than centralized planning. Understanding contingency can transcend the “but it’s not like that where we are” arguments that often get in the way of sharing information and practices in order to improve the working (and thinking) lives of actual people. As an example: the discourse of “center envy”–by which the speaker positions herself in comparison to a colleague at another institution who has more resources and can ostensibly accomplish more. If only we had more resources, a physical center, dedicated programmers, graduate students, postdocs, grants–the myth of scarcity shapes so much of how we think of DH inhabiting our institutions. Perhaps there’s no idealized arrangement for DH that would transcend local cultures; certain institutional configurations, like the small liberal arts college, may indeed be richer and more equitable environments for producing DH work. We may find ourselves comparing irrational institutional arrangements because all academic institutions are absorbed by the supposed rationality of the technology stack, but this is not the most productive way to understand the social conditions of academic labor.
Parallel to Liu’s discussion, Martin Paul Eve has recently argued in the context of open access publishing that the challenges we face in both supporting and crediting scholarship are not technological but social. When infrastructure is understood as an irrational social formation, emotional labor tends to compensate for a perceived lack of resources. Scholars who are used to the invisibility of traditional library services, for instance, find that digital projects expose hierarchies and bureaucracies that they don’t want to negotiate or even think about, and the DH librarian or one of her colleagues steps in to run interference. Why can’t the dean of libraries just tell that department to create the metadata for my project? After all, they already create metadata for the library’s systems. Why can’t web programming be a service you provide to me like interlibrary loan? I thought the library was here to support my scholarship. Why can’t you maintain my website after I retire–exactly the way it looks and feels today, plus update it as technology changes? In some conversations, these questions may be rhetorical; it may take emotional labor to answer them, but doing so exposes the workings of the library’s infrastructure–its social stack.
The Physical Stack
Scholars often presume that because libraries acquire, shelve, and preserve the print books that they write, that the same libraries will acquire, shelve (or host), and preserve digital projects. In her volume Bookshelf (Bloomsbury, 2016) for the Object Lessons series, Lydia Pyne describes how the cast-iron bookstacks manufactured by Snead & Co. around the turn of the twentieth century transformed library architecture and services. Standardized shelves enabled libraries to house more on-site collections, which in turn allowed open-stack browsing. Cast-iron stacks were the literal infrastructure that held up buildings, as the New York Public Library infamously discovered when it proposed to remove book stacks from its flagship Fifth Avenue location. If the university is what Shelby Foote apocryphally called “a group of buildings gathered around a library,” then the library might be a building gathered, or built around–on, out of–book stacks. Book stacks literally undergird (in the sense that a bookshelf is a small girder) the modern university.
Where are the stacks for a digital project? What does the architecture of the physical stacks — the core collections–suggest about how we might arrange (or derange) our digital scholarship? While libraries might be the organizations on campus best suited to arrange, acquire, and preserve digital scholarship, not all scholars think so, if repositoryparticipation rates are any evidence (and they might not be). Scholars may be extrapolating from their experiences with commercial ebook and journal publishers, and we can’t blame them for some apprehension. If publishers can revoke access to digital material at any time, libraries must resist to insure the free exchange of information, and advocate for alternative scholarly economies. As Pyne discusses, digital rights management is the new “chain” that secures books to shelves; unlike the chains that bound medieval codices, “digital chains are just more difficult to see.”[3. Pyne, Lydia, Bookshelf (New York: Bloomsbury, 2016), 27.] As with Bratton’s technology stack that absorbs local decision making and curation of collections, digital chains obscure the agency of librarians and scholars.
# # #
Speaking out about the very real conditions under which digital scholarship is produced and accessed can also reveal long histories of labor inequities in the academy. Thinking about stacks–technological, social, physical–as frames is not a foolproof approach to making this labor visible, nor do my conceptualizations lack inconsistencies. My thoughts are intended to open a conversation, here on dh+lib, on social media, and at conferences and in further publications. And while DH may be particularly generative, as a community of practice, to facilitate these conversations, we are by no means the only ones doing so (or who should be doing so). Making the digital stacks transparent and visible–as visible to library users and as fundamental to our libraries’ infrastructure as cast-iron book stacks are–should be our responsibility as librarians. Not because we need yet another responsibility, but because we are uniquely positioned to interpret the rapidly changing landscape of digital scholarship for all those with whom we collaborate.
It is with a mix of sadness and gratitude that we announce that Caro Pinto, who has served as an editor for the dh+lib Review since 2013, will be stepping away from her role with the Review. Caro has written dozens of Review posts over the past four years, and has shaped hundreds more. Caro’s first contribution to dh+lib was an original post called “Digital Humanities is a Team Sport: Thoughts on #DHTNG,” in which she reflected on the 2013 “DH: The Next Generation” gathering in Boston. She served as one of the Review’s first editors-at-large, a group which has grown to include over 400 of our colleagues.
Caro’s continuous and attentive contributions to the Review have helped us to further the conversations on digital humanities among the library, archive, museum, and gallery communities.
Caro will remain a contributing editor for dh+lib, and we look forward to working with her again in the future.
Thanks for all of your kindness, support, and hard work, Caro!
Many of our readers may remember (and miss!) the annual list of digital humanities sessions at the Modern Language Association (MLA) conference created by Mark Sample (Davidson College). This year, we’re fortunate to have at our disposal a community-sourced spreadsheet, created by Carrie Johnston (Wake Forest University) and containing 52 sessions relevant to digital humanities.
A few sessions of particular interest to librarians and archivists engaged with DH are included below. The full conference program is also available online.
Program arranged by the MLA Strategic Initiatives Workshops
Presiding: Raymond G. Siemens, Univ. of Victoria
Speakers: Melissa A. Dalgleish, York Univ.; Rebecca Dowson, Simon Fraser Univ.; Diane Jakacki, Bucknell Univ.; Aaron Mauro, Penn State Univ., Erie-Behrend; Daniel Powell, King’s Coll. London; Lynne Siemens, Univ. of Victoria
Description: This workshop offers participants both theoretical and hands-on considerations of digital humanities (DH) tools, software methodology, context, and theory; professionalization for early-career scholars; DH for academic administrators; DH and the dissertation; and scholarly communication as public engagement. Preregistration required.
Program arranged by the forum TM Libraries and Research
Presiding: Brian Rosenblum, Univ. of Kansas Libraries
Speakers: Hannah Alpert-Abrams, Univ. of Texas, Austin; Rachel Buurma, Swarthmore Coll.; Amy Earhart, Texas A&M Univ., College Station; Amanda Licastro, Stevenson Univ.; Shannon Mattern, New School; Dot Porter, Univ. of Pennsylvania
Session Description:
Creating access to collections through digitization shapes scholarship and teaching. Panelists open the black box of digitization workflows by discussing how collections are selected for digitization; the process of creating OCR (optical character recognition) transcripts, databases, and metadata for searchability; and the development of user interfaces and open-access policies.
Program arranged by the forum TM Bibliography and Scholarly Editing and the American Literature Society
Presiding: Anna Mae Duane, Univ. of Connecticut, Storrs
Speakers: Sigrid Anderson Cordell, Univ. of Michigan, Ann Arbor; Jim Casey, Univ. of Delaware, Newark; Melissa Dinsman, York Coll., City Univ. of New York; Amy Earhart, Texas A&M Univ., College Station; P. Gabrielle Foreman, Univ. of Delaware, Newark; Jessica Gordon-Burroughs, Hamilton Coll.; Carrie Johnston, Wake Forest Univ.; Elizabeth Rodrigues, Grinnell Coll.
Description: Panelists explore the intersection of digital humanities and the recovery of forgotten, lost, or disintegrating texts and archives. Considering the volume of digital materials now available and the emergence of new tools, how has DH altered both the archive and the project of recovery? What work needs to be done to guard against future gaps in the record?
Program arranged by the MLA Committee on Information Technology
Presiding: Shawna Ross, Texas A&M Univ., College Station
1. “The Human Computer Project: African American Women at NASA, 1943–70,” Duchess Harris, Macalester Coll.; Francena Turner, Univ. of Illinois, Urbana
2. “Early Histories of OCR (Optical Character Recognition): Mary Jameson and Reading Optophones,” Tiffany Chan, Univ. of Victoria; Jentery Sayers, Univ. of Victoria
3. “Pan-American Made: Archival Work at the University of the Air,” David Squires, Washington State Univ., Pullman
4. “Vital Work: Information Science and Invisible Labor in The Infernal Desire Machines of Doctor Hoffman,” Madeleine Monson-Rosen, Loyola Univ., Baltimore
Presiding: Lauren Coats, Louisiana State Univ., Baton Rouge
Speakers: Gabrielle Dean, Johns Hopkins Univ., MD; Katherine D. Harris, San José State Univ.; Melanie Micir, Washington Univ. in St. Louis; Charlotte Nunes, Lafayette Coll.; Ivy Schweitzer, Dartmouth Coll.
Session Description:
Panelists present specific archival dilemmas or experiments as a means of identifying and exploring archival boundaries as sites of transformation in teaching and scholarship.
Finally, if you’re an information professional attending the MLA conference, consider writing up your experience for us! Email dhandlib.acrl (AT) gmail (DOT) com to send us a pitch. And say hello to Patrick Williams, our Lead Editor for the dh+lib Review while you’re there.
“How can we move beyond a monolingual DH, and promote exchange of works among linguistic communities? And how can we ensure this exchange is ongoing and sustainable?”
dh+lib has long been interested in tackling these issues for our community of practice. The 2016 Digital Humanities conference will offer an opportunity to design and test an approach: attendees at a July 12 preconference workshop will join dh+lib editors and leaders from Global Outlook::Digital Humanities (GO::DH) and the Libraries and DH SIG (both Alliance of Digital Humanities OrganizationsSpecial Interest Groups) in an attempt to take up these questions and hack a solution.[1. The full list of workshop organizers: Sarah Potvin (Texas A&M University), Élika Ortega (University of Kansas), Isabel Galina (National University of Mexico), Alex Gil (Columbia University), Daniel Paul O’Donnell (University of Lethbridge), Patrick Williams (Syracuse University), Zoe Borovsky (University of California Los Angeles), Roxanne Shirazi (City University of New York), Zach Coble (New York University), and Glen Worthey (Stanford University). Additional thanks to dh+lib editor Josh Honn (Northwestern University) for helping to forge a dh+lib approach to translation.]
The workshop will introduce translation work and practices, and move towards developing a pilot translation process for dh+lib with potentially broad applicability to other scholarly communication vehicles and venues. The group will think through existing infrastructure, address questions around translation, labor, and design, and perform hands-on translation. We will build on previous translation exercises put into practice by GO::DH and dh+lib, including DH Whisperers, thesimultaneousbilingual publication of blog posts, and the newly-created GO::DH Translation Toolkit.
The weekly dh+lib Review is made possible by more than two hundred volunteer editors-at-large, four Review editors, a handful of dh+lib editors, PressForward developers, and American Library Association technical staff. We think a community translation effort will need to build upon and extend these generous contributions.
As a first step: we’d like the hands-on translation efforts undertaken at DH2016 to focus on works nominated by the DH and libraries community. Isabel Galina has pointed to “… a general perception of an Anglo-American dominance and English language as the main language” in DH, observing that, even when vibrant DH unfolds in, for example, German- and French-language communities “… a lack of publications and communications in English leads to invisibility on the mainstream channels.” While translation may ultimately proceed in multiple directions, we’d like to start with non-English language works that you want to see translated into English, to address the gap that Galina describes.
In the interest of visibility, transparency, and ease of participation, there are two ways you can nominate content:
Tweet a link to the work, with the hashtag #GOdhlib