My digital humanities center recently returned to a renovated library building with a dedicated public area. Our pre-renovation space included semi-public shelves full of DH-relevant books, but by 2019 thirteen years of book accrual meant our specialized reference collection needed significant curation. Some of the most appreciated books weren’t making it back to us, and other books were outdated in terms of whose work we wanted to amplify (e.g. needed to remove known bad actors, balance a non-representative number of white male authors), as well as technology (so many 1990s PHP textbooks!).
After cutting down those books to the core we still wanted to keep, we started to plan a goals-based collection rebuild. We’re interested in reparative collecting, so that the reads we amplify show an accurate and inclusive array of what the digital humanities is, as well as making an argument for the DH we want to be [1]. Head of R&D Jeremy Boggs’ project starts from a carefully curated collection of books meant for use during our reference consultations (a “DH Working Library”). He’s building an online interface so our community can browse both the included titles, as well as the lab’s reviews of what we learned and liked about these books. My own project starts from a larger count of “reads” (“SLabReads” [2]), exploring what’s possible for our “shelves” if we first structure items on both our to-read and read lists as a dataset with useful metadata.
“Reads”, not books
My use of “reads” here is precise: I mean not just print books and journals (or their digital versions), but also works in an abundance of other formats. I won’t say I’m including anything that has or could inform and inspire the work of the lab and our community—for example, I’m not including specific people as “reads”—but I do mean that term capaciously. I have been informed or inspired by, for example, a literal bread recipe; fictional or creative work that explores possibilities, or conveys an ethos I took back to my research; tutorials, informal discussions, datasets, infrastructural and administrative work, zines, social media posts, and countless other of the ways humans create and share thinking.
“Generous” citation—in whom we cite [3], and what format their work takes—is actually just accurate citation. Academia routinely lags in citing all the emails, attended conference talks, social media posts, elevator conversations, movies, podcasts, reviewer comments, and more that inspire and inform our scholarship. Similarly, physical displays in academic libraries tend to disinclude relevant reads that aren’t in a print scholarly book or journal format, such as all the formats I just listed—sending a message that other formats or work are lesser, or not relevant. That isn’t only a general loss of what other reads could have been included. Given systemic racism, sexism, and other harms in publishing and academia, limiting ourselves to just some of the most gatekept formats fails at presenting a welcoming, inclusive, anti-racist, and accurate picture of what relevant work exists to inform and inspire around a given topic.
Other areas of my scholarship argue against the perception that work in non-print book/journal formats isn’t useful, relevant, or “scholarly enough”. With my “SLabReads” project, though, I’m working against a different reason we limit the reads we exhibit in our public spaces and our shelves: the practical difficulty of displaying works not designed to sit on a physical shelf.
That’s where the making comes in. The rest of this piece will describe how I’m designing a database of our collection [4], followed by the goals and current status of three of the making projects my database has already powered. Each making project aims at inviting ways to list and amplify relevant reads together in the same public physical display, regardless of formats.
Physical shelves aren’t an accessible location for everyone. My project is based on a digital database, so a catalogue can be accessible online and also encountered in our public space. Future work might include improvements to a catalogue’s accessibility beyond webpage design accessibility, such as optimizing for translation tools, and using minimal computing approaches so accessing a catalogue isn’t limited to those with ample internet bandwidth. I’ve also tried to incorporate physical but off-shelf options in my planned projects, such as the “themed reading card decks” that I share later in this piece.
Database as starter for reading + making projects
Like a single sourdough starter producing a variety of bread, I needed a dataset of my reads, including interesting metadata to help match them to potential readers, to craft multiple paths into our cross-format reads collection. I initially developed two separate datasets: bookmarking cool reads as I heard of them via browser bookmarks and Pinboard; and collecting individual print zines as I came across them, then recording info about each in a Google Sheet. Initial pandemic lockdown, and the desire to include authors and topics I wasn’t coming across when buying zines locally, meant I moved to collecting mostly digital zines. I already don’t buy many print books, so once my zines became more digital too, it became obvious I should collapse the two collections into one cross-format collection.
I use “catalogue” to mean a public interface to browsing and searching my collection database. I use “database” to mean the relational database place where I work directly with the data. The latter is optimized for bulk editing (e.g. for every time I add a new metadata field), and for the key thing that separates a relational database from a spreadsheet: defining a single instance of a record that can then be linked from various data fields and displays, rather than repeating information that already exists. For example, new reads entries automatically can refer to other works by the same author, by referring to a single existing instance of that author from a dropdown; I don’t need to re-enter the author’s name every time I input one of their works, hoping I spell and format it the same way every time so searching doesn’t miss any of their works.
Approximating a database in various online spreadsheets (e.g. Google Sheets, Excel Online) quickly produced unacceptable lag time while editing. An option billed as an open-source and self-hostable Airtable (Baserow) was promising, but after running into a few glitches and lags, I wasn’t willing to trust my data there. I’m currently using the free version of Airtable, which has the most user-friendly interface I’ve encountered for free or non-enterprise price, both for the database developer and for exposing public catalogue views of subsets of the data. I’ll eventually run into their data limits, and need to pay for an advanced plan or move elsewhere.
There are other, easier, and/or cheaper ways to approach this kind of data work; this is just what’s worked for my particular needs. Using a relational database with a shiny user-interface like Airtables’s means I can take a collection where a small slice of the entries and their metadata looks like this, organized by title…
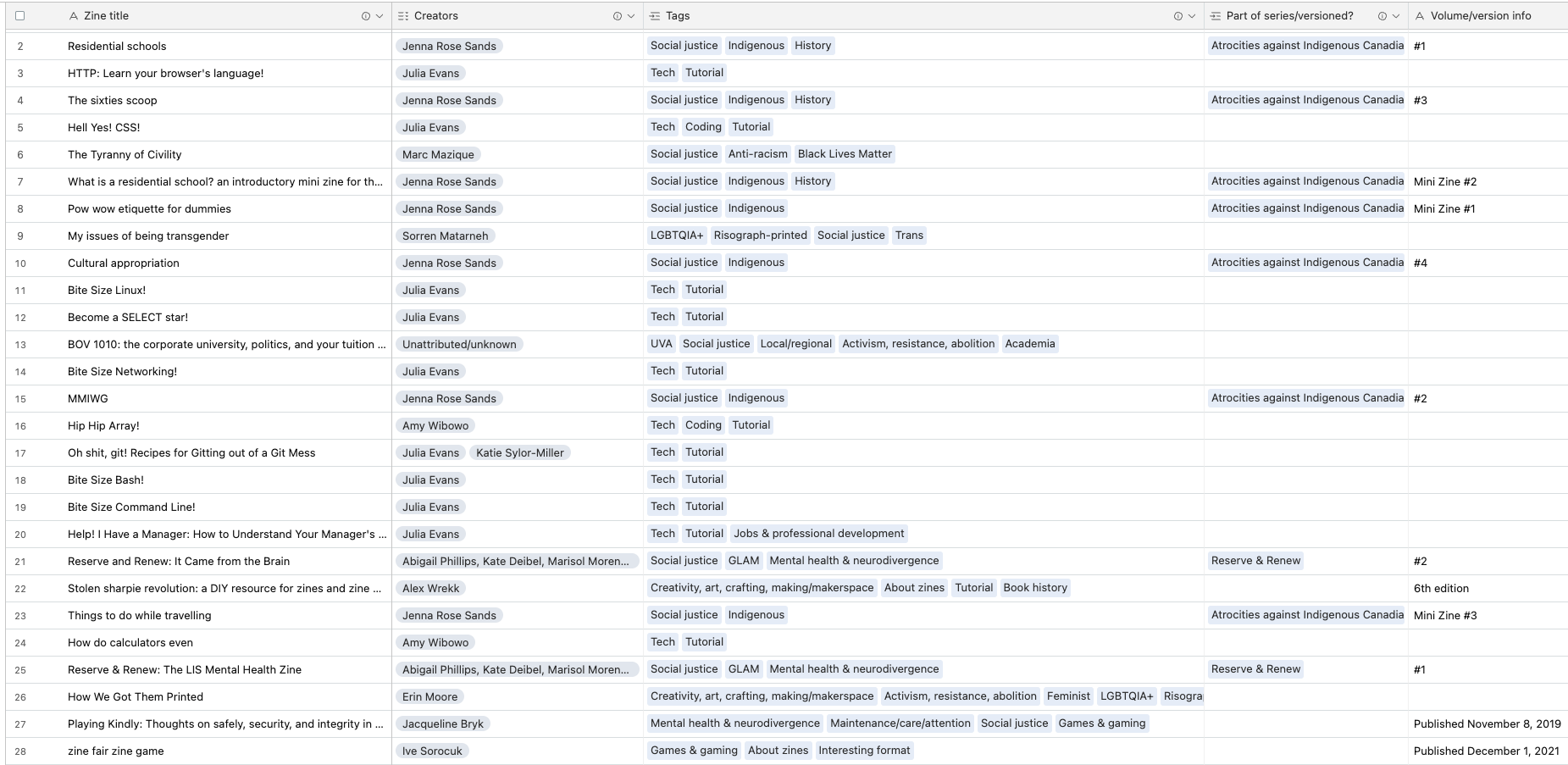
Image 1. Small slice of the reads database entries and their metadata, using the main title-based data view.
…and then easily pull data and view by other metadata fields, such as a zine’s status on my physical “zine wall” display…

Image 2. Slice of the reads database “wall status” view, which I use to track count, location, and reprint needs of my collected zines.
…or which zines cover which of the tagged topics of interest to me:

Image 3. Slice of the reads database “tags” view, which I use to see which and how many zines are tagged with what themes and topics.
Currently, only a subset of my reads collection (a little over 100 zines) and its metadata (18 of 30 fields) are exposed as a public catalogue. I’ve focused on creating and filling out metadata fields that I know will power things I want to do, such as seeing how diverse the authors are, respecting authors’ explicit directions regarding IP (e.g. remix, sharing person-to-person vs. broadly, replicating from one print copy), and recording whatever I can toward making an ethical choice about preservation, sharing, and remix when that information is not explicitly stated. I made a bar chart showing me which thematic tags are most used, so I can identify topics where I need to collect more, or have enough reads to create some themed making project. If I don’t have a specific use in mind yet for some aspect of my zines, I keep things wieldy by not creating a field for it—for example, I could record zine binding style, but don’t know how I’d use that info yet so have not created a field for that metadata.
I know it’s weird to go from “include all the formats!” to “but just zines for now!” I have hundreds more collected non-zine reads to add to the database, in addition to hundreds of additional zines to add, but I’ve found that 100 items is enough to start doing interesting things with data filtering and sorting by metadata. The zines had the most metadata already recorded when I decided to combine all my formats into one collection. Starting out with just one (not print book or journal!) format helped me focus on filling out all the metadata I’d want for each of those reads. Seeing at a glance if something was missing data, instead of needing to look back at the title each time to tell whether the metadata field applied to the read or not, has helped me get a full pilot database up to start experimenting with. For example, an interactive digital tarot deck won’t use the zine fields for reprinting policy, zine layout type, or number of copies currently printed fields; and might have fields for non-zine features like how much bandwidth the website takes to load, or coding languages used to make the site.
So how does this dataset power makerspace projects? In the remainder of this piece, I describe three of the in-progress reads and making projects that my dataset has enabled [5].
Themed reading card decks
Why: Demonstrate the possibilities of the thematic metadata in my reads catalogue; potentially pull different formats of reads into the same list; create a fun, portable way to take syllabi or other themed reads lists away from our physical space, or hand them out at events.
Design: I designed and printed a deck of “playing cards”—just like standard poker cards, except the only text and graphics was what I designed [6]. These cards collect recommended zine readings about DH making and other topics of interest to me, one read per card. I was inspired by SLab colleagues’ past projects that use “card decks” to link you to various media: Ammon Shepherd blogged the RFID storyteller machine he built that lets kids select from a deck of stories, and Arin Bennett made a short video of the RFID jukebox he created, which opens Spotify links from cards.
Each card displays a work’s title, creators/authors, and a QR code on one side. Scanning the QR code with a smartphone brings you to a webpage where you can read the zine for free. The “recipe” at the end of this article (and in the associated zine!) contains further details on designing and creating a similar deck of your own, so check there for further details about the design of this prototype (and how to create your own).
Building status: Fully prototyped. I created a small themed card deck as my contribution to ACH 2023 conference’s #DHMakes [7] team submission, and sent it to be added to that session’s larger DH making project. In line with my goals for inclusive reads amplification, this initial card deck contained reads I’d thematically tagged in my zines catalogue as related to LGBTQIA+ experience and rights, anti-racism, labor, and feminism.

Image 4. Example themed reading card deck, prepared for the ACH 2023 conference’s #DHmakes (digital humanities making) session.
Ghost Books (modeled on Aidan Kang’s Luminous Books)
Why: Shelvable, book-shaped glowing invitations to amplify non-book reads right amid print books on a shelf.
Design: I like neon signs, but given the difficulties of creating true neon signs (glass! gas!), I’ve been experimenting with EL wire and LEDs to approximate the neon look more safely and inexpensively. Researching projects combining light and books, I found a number of neat projects that converted existing books (e.g. Steve Hoefer’s “Not Your Ordinary Book Light”). Aidan Kang’s Luminous Books [8] best met my goal of drawing book-like attention to non-book reads and fit my developing skills using LEDs and laser cutters.

Image 5. Materials for the Ghost Books project, including blue LEDs with silicone diffusion, superglue, acrylic and glass cut to size with smoothe or crenellated edges, and one of the books I’m basing the initial prototype on (10 PRINT).
My Ghost Books project is an attempt to make a crude approximation based directly off several photos of Kang’s elegant work. Could I figure out how to make something less beautiful, but with the same core components of LEDs, transparent book-shaped box, and translucent “book” cover? The “ghost” in the project name comes from this last component: can I come up with a visually appealing “cover” template for reads that don’t have covers of their own?
Building status: Early prototyping. I’ve sketched the project, and acquired materials to create two test Ghost Books.
Case. I used an online tool [9] to design laser cutting files to create the flat shapes to assemble into two rectangular prism book cases, and left a cutout for accessing the LEDs inside after the case is glued shut. I’m initially trying this with both glass and thick acrylic to see how each material works once it’s sitting on a shelf. I sized these two cases to match my hardback copies of Safiya Noble’s Algorithms of Oppression and Nick Montfort et al.’s 10 PRINT, as both had covers that might look good with light shining through. I started this project during the pandemic when I didn’t have access to a laser cutter, so I paid an online company (Ponoko) to laser cut and ship me the pieces needed. If these prototypes go well, I’ll experiment with making the case more book-shaped (e.g. Kang’s have rounded spines) and design a sliding piece or hinge into the case, so it’s easy to replace LEDs and covers.
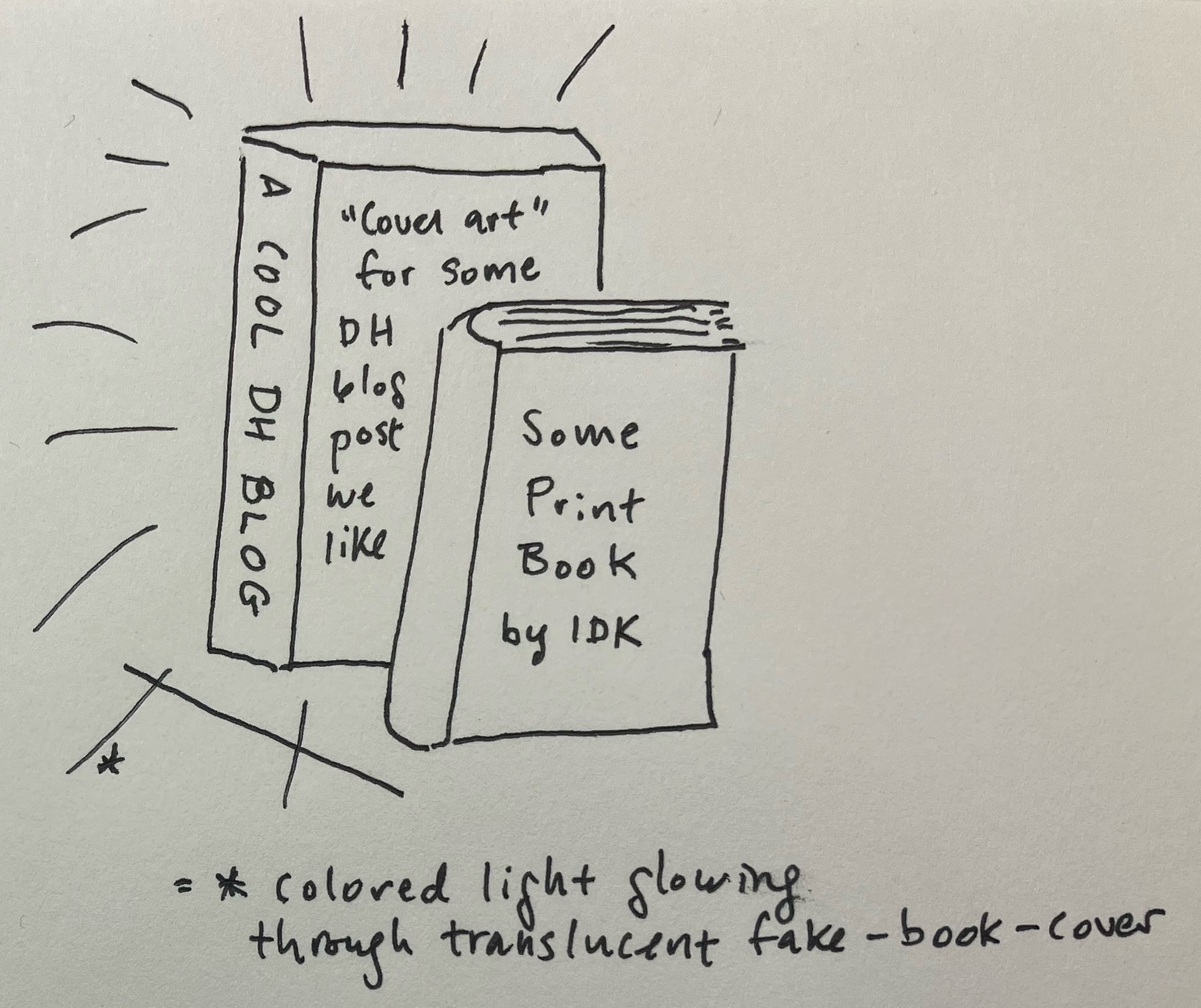
Image 6. Author’s sketch of what the final Ghost Book should look like.
I read Make.Share.Learn‘s acrylic display case tutorial to get a rough sense of how to design and assemble a case. I intended to use a transparent glue to put the pieces together into the cases, but I wasn’t sure whether flat or crenellated edges would keep the pieces together best, so I designed one of each to test. The pieces arrived cut to easily pop out of a larger rectangle, so I have extra material I’m now using to test gluing and clamping, before trying this on the actual case pieces.
Lights. I used a strip of blue LED bulbs and a piece of silicone half-tubing, which diffuses the LEDs when placed over them so the light looks more like continuous neon than separate dots. I’ll place this inside the case inside the cover once it’s ready, and get a sense of what cover materials allow the right amount of light to shine through. I also ordered a NeoPixel addressable LED strip, with the idea that I could make the lights slowly change color or pulse (“addressable” means I can send commands to the LED bulbs to change their color etc.). For this work, I used AdaFruit’s NeoPixel guide to ID the power adapters, microcontrollers, and cables I needed to light these up, and have started following their guides on how to program the addressable LEDs.
Cover. For the initial prototype, I’m using the actual covers of the two books named above, so I can focus first on the electronics and assembly work for which it’s less obvious what I need to do. If those work, I need to design fake “book covers” for any non-book reads I’d like to display. I’ll need to look if a given read has any associated art online, find stock illustrations to reuse, or try getting OpenAI’s image tool to create usable art. I’ll need to design the title and author text, and add a QR code so that viewers can easily go from looking at the Ghost Book to looking at the actual read it represents.
Mini Book List Printer (modeled on SailorHg’s “While(Fruit)”)

Image 7. Author’s sketch of what the final Mini Book List printer should look like.
Why: We’ll create a digital interface to browse our mixed-format reading collection, and can make that catalogue usable from our public space via a computer workstation; adding a printer lets users take a list of reads they discover away with them. But a plain PC and printer doesn’t scream “discover cool reads here, including stuff not visible on the book shelf”—and does invite people to try to do unrelated things like checking email. I wanted a case that invites curiosity, and gives users a fun enough experience they might mention it to other people.
Design: I’m building a transparent green neon acrylic case, roughly shaped like a retro Apple computer (Mac Classic II), to draw visitors to a desk where they can interact with our catalogue. Apple has a history of transparent cases for prototyping [10], and more recently artists have made their own transparent cases for actual Apple hardware [11]. I am heavily inspired by and modeling my case’s look directly on SailorHg’s “While(Fruit)” exhibit, which simplifies the Mac Classic silhouette and combines neon transparent acrylic with cool retro programming art [12].
Inside, a small display screen will act as the case’s “monitor”; a Raspberry Pi allows users to access the reads database; and a mini thermal receipt printer will print out small (receipt-width) paper reading lists through the “floppy disk slot”. Users would be able to take a quiz that filters catalogue metadata (especially the thematic tagging) to produce a short recommended reading list; they would also be able to browse the entire database and mark any titles of interest for inclusion in a reading list.
Building status: Early prototyping.
Case. I’ve prototyped the retro Apple case to full scale using cardboard. I acquired acrylic samples to test color and thickness, as well as samples of straight and crenelated acrylic edges to test which provides the sturdiest and prettiest outcome, when glued together to form the computer case. Once our new laser cutter is available later this spring, I can purchase and cut acrylic to size and assemble the final retro Apple case.
Microcomputer, interface, printer. For the digital components, I’m halfway through setup of the Raspberry Pi and receipt printer, using Phillip Burgess’s “Internet of Things Printer for Raspberry Pi” tutorial. I’ve created an initial catalogue of 100+ zines and metadata that I can use to code both the quiz and catalogue browsing views. I need to create a connected catalogue of non-zine reads using an overlapping metadata schema, so that more than zines are included. I have an existing list of 300+ non-zine reads I want included in the collection. I’m hoping to work with my lab colleague Jeremy Boggs to connect to his DH Working Library reference collection and catalogue project as well.
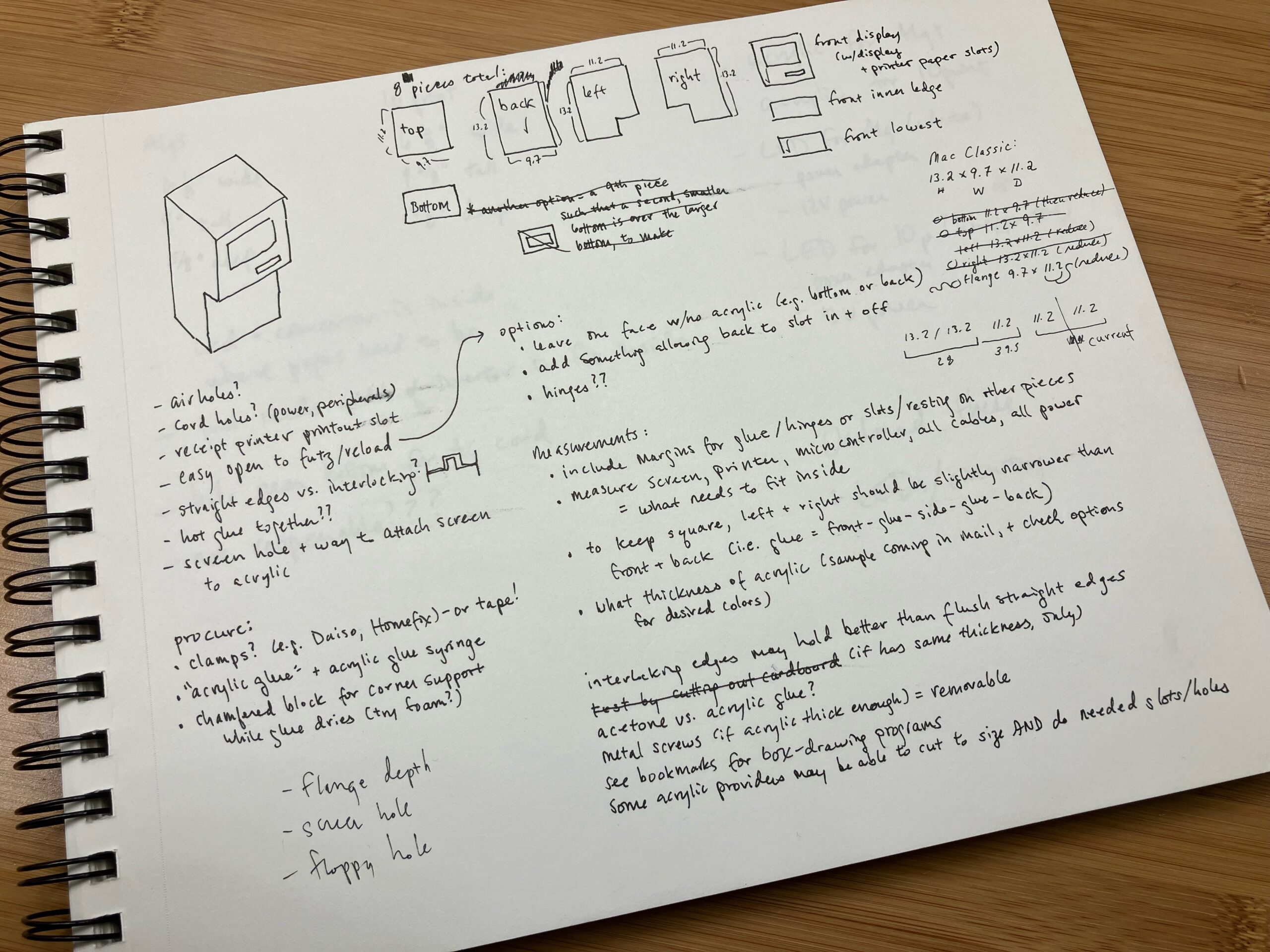
Image 8. Author’s sketches and notes planning the layout of the Mini Book List Printer’s acrylic case.
What’s next?
I’m continuing the planned work on these reads projects and others, and will share their final forms at my research blog LiteratureGeek.com as they are completed. I welcome suggestions of related work to read and cite, relevant things you’ve made, etc. at visconti@virginia.edu. Check out the recipe tied to this article, if you’d like to make a themed reading card deck of your own!
Recipe: Themed Reading Card Decks
Below is a tutorial for creating a “themed reading card deck” similar to what I described earlier in the article. I thank Ammon Shepherd and Arin Bennett for sharing their own card-deck-shaped media projects with me, inspiring this work.
Ingredients
The list below produces 1 card deck; multiply #3-5 by how many decks you wish to create.
- A list of “reads” including titles and links to online locations where someone can access the “read” (or info on otherwise acquiring or understanding it, e.g. a review, a title in a zine union catalogue); if you’re starting from scratch, see the “data prep” section below before making the list so you save time by formatting as the project requires
- Optional: Additional “reads” data you might want to fit onto a card, and/or use to filter down to a set of reads sharing a specific theme or other feature (e.g. authors, themes, methods, formats)
- Access to a printer
- Black and white is fine, if color is unavailable.
- You’ll need to be allowed to switch in label paper and not have someone accidentally print on/use up your special paper while it’s in the printer tray, so if you’re on a public printer you’ll want to find quiet hours.
- 15+ standard-size playing cards
- “15+” is meant to be enough to feel like a “hand” or “deck”; less is fine, but some of the pleasure of the card form comes from things you can do with a normal playing card deck like tapping, sorting, dealing “hands”, fitting into a plastic deck case and/or shirt pocket…
- You can either
- Use existing playing cards you happen to own (note they will no longer be usable as playing cards after), or
- Purchase any blank playing cards (e.g. $9.99 for 180 2.5×3.5”cards on Amazon)
- Optional: If you want to be extra-fancy and have access to a printer that is able to handle the small size and rounded corners of blank playing cards, you may want to look into whether glossy vs. matte blank playing cards work best with your printer’s ink (e.g. vs. smearing). My instructions assume you’re using Avery printing labels; if you find blank cards that work with your printer, you can print to the cards directly and not purchase/use the labels.
- A playing-card case, either
- A clear plastic deck case (e.g. $15.99 for 15 clear plastic cases on Amazon), or
- An existing playing-card deck box, or
- Silicone earplugs are sometimes sold in a clear plastic case that can fit a deck
- Blank, printable labels to affix your content to the cards (e.g. $16.91 for 160 Avery printable name tags on Amazon)
- You need 2n+3 labels, where “n” is the number of cards you want in in your deck (covers card backs and fronts, a case label, and 1 Joker/info card with details about the whole deck)
- I used Avery printable name tags (product #8395), which allowed me to use Avery’s label design tool; while not required, this recipe gives some extra tips that are only useful if you’re also using Avery labels
Steps, Part 1: Data Prep
Getting your data into a format that allows easy printing to the playing cards.
- My reads catalogue lives in AirTable, but AirTable’s printing extension is not great. I exported info from to a CSV, then uploaded it to a Google Sheet as that’s my most comfortable spreadsheet manipulation place.
- You will need at least one column containing the URLs you want QR codes to bring you to.
- To generate the QR codes from your column of URLs:
- Refer to each cell in the URL column like “A2” in this example, to call the Google API and create the QR code: =IMAGE(“https://chart.googleapis.com/chart?chs=200×200&cht=qr&chl=”&ENCODEURL(A2))
- You may need to accept a prompt to allow Google to get data from external parties.
- If you’ve got the sheet set to display formulae, toggle that off to see the QR codes
- Copy-“paste as value” the generated QR codes to stop them from being tied to underlying formula/references.
- Download the file as a CSV
- I wasn’t able to get the QR codes into the Avery program (didn’t see a way to download/import a Gsheet/CSV that preserves the QR images), so I just took a screenshot of each QR code and dropped it onto the labels, when at the editing individual labels stage.
- Refer to each cell in the URL column like “A2” in this example, to call the Google API and create the QR code: =IMAGE(“https://chart.googleapis.com/chart?chs=200×200&cht=qr&chl=”&ENCODEURL(A2))
Steps Part 2: Design
You can use any graphics or document mail merge tool that lets you layout/print in a way that gets the ink on your card labels right; many label brands offer either tools, or at least document setup guidelines to help you print within each label’s boundaries.
I used Avery brand labels, so I used their free online tool to lay out my cards; that tool manages keeping your design within printing error margins, and allows you to easily repeat the design elements you want to appear the same on all cards.
- Tips:
- Being certain about the tool printing correctly re:label edges/margins for error was helpful; you input the Item # of the Avery product, and choose or create templates to lay out using those dimensions.
- I had trouble getting the text size settings I wanted—some of my reads titles are short, some are very long; ditto creators names list. So for this first car deck, I limited the text to title and creators. In the future, I can either individually resize titles that get cut off, or move to a different tool that allows sizing to automatically fit input text length.
- I picked a template that would work with a non-color printer, merged in my CSV, placed the title and creators data, and finished making edits to the default template.
- Switching to editing the label individually, I pasted in the QR code screenshot for each.
- I printed 4 different layouts, to cover:
- Card reads info labels (the titles, creators, QR codes)
- A label for the outside of the deck case
- A label for one Joker/“info” card to include in the deck, with some text about what the deck is
- Labeling the backs of all the cards (same design for each, in case you want to play a card game… somehow…)
Steps Part 3: Printing
These instructions may need tweaks to work with other printer models. For a Brother HL-L2350DW and its defaults:
- Put Avery sheets in so that the “front” (the part you’ll look at when peeling the labels off) faces down (not upward toward you)
- Make sure double-sided printing is off
- Make sure scale is set to 100% (not auto-rotating/best fit)
- Use the settings for media/quality heavyweight paper and best quality
- Test print on non-label paper first—I have to fight my brain on this every time, but an extra minute of your time is worth not ruining some of your limited set of label papers
- Print to the label paper
- Affix labels to cards and deck case. Your themed reading card deck is complete!

Image R1. Here’s Dr. Cheese Bones wearing the ACH 2023 #DHMakes crew’s collaborative DH making vest, with one of my themed reading card decks tucked in its pocket (circled). Photo and Dr. Bones appearance by Quinn Dombrowski; the wonderful folks who made the various pieces of data quilt, felted text etc. attached to the vest are Quinn Dombrowski, Claudia Berger, Jojo Karlin, Alix Keener, Anne Ladyem McDivitt, and Jacque Wernimont.
Endnotes
[1] Thanks to Élika Ortega for planting the framing of “what DH could be” in my head early in my involvement with the eternal “define DH” conversation, and to all her scholarship modeling how to take active part in moving us toward a better and more just DH.
[2] “SLab” is short for Scholars’ Lab; “reads” is my term for readings not limited to print books; and running the two together creates the word “breads”, which is pleasing to someone whose research writing includes the title “A digital humanist can have a little bread, as a treat“.
[3] The Cite Black Women Collective‘s Praxis page is a good place to start, if the non-accuracy of who we do and don’t cite isn’t a topic you’ve spent time considering before.
[4] In addition to the making possibilities this piece explores, creating a database from things I like to read, from zero entries up, only including the metadata I care about has been fantastic for learning new and brushing up old old database-related skills.
[5] There are more! I’ve started assembling a split-flap text display exhibit, but the other ideas are only in their earliest “wouldn’t it be cool if” stages.
[6] Some of this section and the associated “recipe” text are drawn from my earlier writing for the Scholars’ Lab blog and #DHMakes ACH 2023 conference session work. Thanks to the ACH 2023 #DHmakes crew of Quinn Dombrowski, Claudia Berger, Jojo Karlin, Alix Keener, Anne Ladyem McDivitt, and Jacque Wernimont for inspiring me to move forward on this project!
[7] #DHmakes is an active hashtag on Bluesky and Mastodon for folks who are DH-curious or -adjacent to share craft and making things they’re working on regardless of the thing’s relevance to DH or their work. We’d love to see your work—please consider posting using that hashtag!
[8] For more information and photos, see also https://www.artsy.net/artist/airan-kang, https://www.theparisreview.org/blog/2015/05/06/the-luminous-poem/, and this uncredited image that appears to show a bit of one od the books’ hardware https://inhabitat.com/wp-content/blogs.dir/1/files/2016/05/Light-Reading-Airan-Kangs-luminous-LED-books-are-truly-a-bright-idea-controls-889×592.jpg
{kind=link}
[9] I unfortunately did not record which tool I used; it may have been Makercase.
[10] See https://images.fastcompany.net/image/upload/w_596,c_limit,q_auto:best,f_auto/fc/1672977-inline-rvw62n6njpgpart.jpg for an uncredited photo of such a transparent prototype from a 2013 Fast Company piece by Margaret Rhodes on “Christie’s Auctions Off Apple’s Rare, Iconic Designs”.
{kind=link}
[11] See https://pbs.twimg.com/media/FVvwhEqWQAAiUnl?format=jpg&name=small for an uncredited photo of a custom translucent green classic Mac case included in Twitter user @dystopria’s tweet at https://twitter.com/dystopria/status/1539488354277986304
[12] The show’s webpages have since broken, but in February 2024 you could still view photos via several social media and store links, including https://www.instagram.com/p/CVyFWNYPFf1/?hl=en&img_index=1, https://twitter.com/CAPSULE_CORNER/status/1460416702655569921, and https://andand.gallery/product/blueberry/.
Amanda Wyatt Visconti
Dr. Amanda Wyatt Visconti (they/them) directs the Scholars' Lab, an experimental and digital humanities research center at the University of Virginia known for its "people over projects" focus. They are an appointed officer of the U.S.-based, international-membership DH scholarly organization the Association for Computers and the Humanities. Previously, they were a tenure-track DH professor at Purdue University. They hold a Literature Ph.D. achieved through a pathbreaking, no-chapters DH dissertation; and an Information M.S. specializing in DH human-computer interaction. Visconti regularly shares research (including early- and mid-stage) on social media (bsky.app/profile/literaturegeek.bsky.social) and by blogging (LiteratureGeek.com). Their interdisciplinary interests include designing just and caring digital scholarship infrastructure, collective spaces of learning and solidarity, and zine materiality.
- Web |
- More Posts